지난 포스팅에서 다룬 Self-supervised Pre-training Model GPT-1, BERT에 이어서 Advanced Self-supervised Pre-training Model GPT-2, GPT-3, ALBERT, ELECTRA에 대해 살펴볼 것이다.
https://amber-chaeeunk.tistory.com/97
[NLP] GPT-1 , BERT
오늘 소개할 자연어 생성 모델인 GPT-1과 BERT는 모두 Transformer에 기반을 두고 있기 때문에, 만약 Transformer에 대해 잘 모른다면 아래 링크에서 Transformer를 먼저 학습해주세요! https://amber-chaeeunk.ti..
amber-chaeeunk.tistory.com
GPT-2
기존에는 다음에 올 문장을 예측하는 Binary-classification task와 how are you? 질문에 대한 답을 예측하는 task는 서로 다른 task로 모델 구조가 달랐다. GTP-2는 다양한 NLP task를 Question Answering task로 통합하였다.

예를 들어,
· 문장의 긍/부정을 예측하는 Binary-classification task의 경우, What do you think about this document in terms of positive or negative sentiment?와 같은 질문을 추가할 수 있다.
· 문장을 요약하는 task의 경우, What is the summary of the above paragraph?의 질문을 추가할 수 있다.
· 번역 task의 경우, What is translated sentence in Korean?이라는 질문을 추가할 수 있다.

■ GPT-2의 Dataset
양질의 데이터셋을 확보하기 위해 Reddit이라는 질의응답 플랫폼에서 답변에 포함된 링크 중 좋아요를 3개 이상받은 데이터 등을 가져왔다.

tokenize할 때는 word단위가 아닌 BERT의 sub-word로 나누는 WordPiece와 유사하게, Byte단위로 잘라서 분석한 후 나누는 BPE기법을 사용하였다.

※ BPE 참고자료 https://wikidocs.net/22592
■ GPT-2의 Model 구조
GPT-1의 구조와 비교하였을 때, 주된 변화는 Layer normalization의 위치가 이동한 것과 위쪽의 Layer로 갈 수록 그 수행 영향력이 줄어들도록 설계한 것이다.
(추가 설명 작성하기)

■ NLP task 결과
· Question Answering task 결과
GPT-2의 LM은 Zero-shot setting으로 down stream task를 수행할 수 있다고 하였다. 따라서 어떠한 fine-tuning없이 CoQA데이터셋을 학습하는 실험을 하였는데, 그 결과 F1 score55의 성능을 보였다. Fine-tuning을 했을 때 F1 score89를 달성했지만, Zero-shot setting에서도 55%의 괜찮은 수행 결과를 내었다.

· Summarization task 결과

· Translation task 결과

GPT-3
GPT-3은 GPT-2를 발전시킨 모델로 구조에 변화는 주지 않았지만, 더 많은 데이터를 사용하였으며 Self-Attention Layer를 많이 쌓아 parameter수를 대폭 늘림으로써 높은 성능을 달성했다.
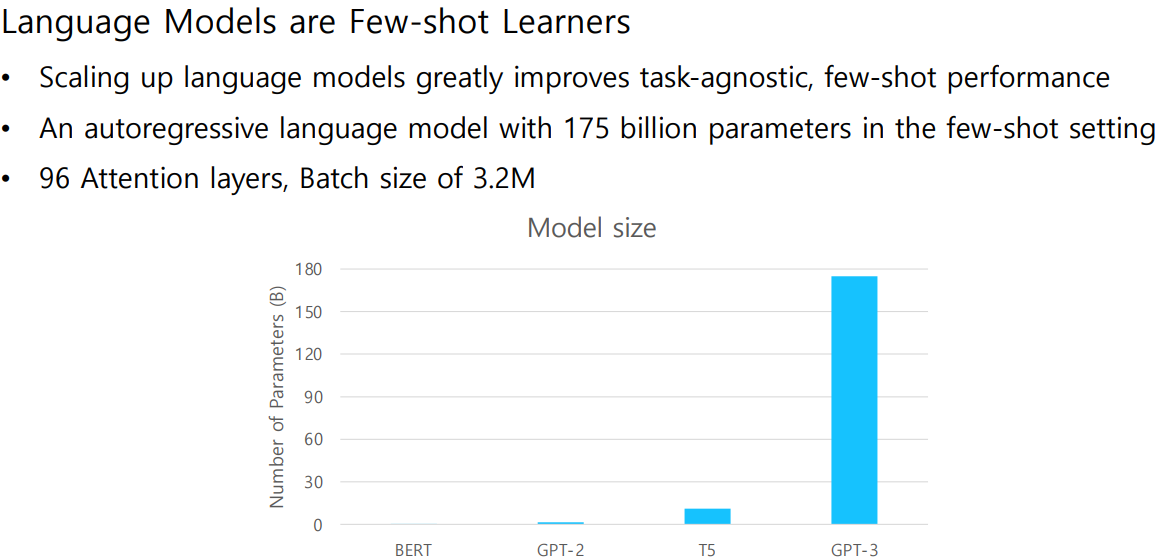
GPT-3는 GPT-2의 Down-stream tasks in Zero-shot setting의 가능성을 보고 Few-shot setting으로 발전시켜 fine-tuning 없이도 좋은 성능을 낼 수 있도록 하였다.

아래 그래프를 보면 Dawn stream tasks in Zero/One/Few-shot setting은 모델 사이즈가 클 수록(=Parameter수가 많을 수록) 더 좋은 성능을 내는 것을 확인할 수 있다.

ALBERT
'ALBERT is A Lite BERT for Self-supervised Learning of Language Representations'
ALBERT는 BERT의 경량화된 모델이다.
기존의 NLP모델은 점점 큰 모델과 많은 parameter를 사용하여 성능을 향상시켜왔는데, 이는 메모리와 시간 자원을 많이 필요로 한다. ALBERT는 parameter수를 줄여 모델을 경량화하면서도 좋은 성능을 유지 및 향상하였다.

ALBERT의 3가지 Solution에 대해 자세히 살펴보자.
1. Factorized Embedding Parameterization
BERT는 Residual connection을 위해 모든 Layer에 대해 input vector dimension과 output vector dimension이 같아야 한다. Layer를 거듭할 수록 vector는 더 고차원의 정보를 담게되며, 상대적으로 Block에 처음 들어가는 input vector가 가장 적은 정보를 담고 있다. parameter수를 줄이기 위해 맨 처음 모델에 들어가는 input vector의 dimension을 축소하는데, 그 이유는 그나마 정보의 손실이 가장 적기 때문이다.
아래 그림을 보면 BERT에서 input vector의 dimension은 4인데, ALBERT에서 2로 줄였다. Layer에 넣어주기 전에 4차원의 공간으로 선형 변환하는 행렬을 곱함으로써 input vector와 output vector의 shape을 맞춰준다.

예를 들어, 단어 500개가 있을 때 기존 BERT의 dimension은 100이고 축소한 ALBERT의 dimension은 15라고 하자. BERT의 parameter는 100x500이고, ALBERT의 parameter는 15x500 + 15x100이다. 50,000 > 9,000으로 ALBERT의 parameter수가 훨씬 줄어드는 것을 알 수 있다.
2. Cross-layer Parameter Sharing
모델이 학습하는 parameter는 여러개의 Query, Key, Value를 만들어 내는 WQ, WK, WV 선형 변환 행렬과 그 Multi-Head의 차원을 맞추어주는 WO 선형 변환 행렬이다.

BERT에서는 여러층으로 쌓인 Block들의 WQ, WK, WV, WO parameter가 모두 달랐으며, 각자 학습하였다. ALBERT는 이 parameter를 sharing하는 것을 제안하였고,
· WO만 sharing하였을 때 ▶ Shared-FFN
· WQ, WK, WV만 sharing하였을 때 ▶ Shared-attention
· WO, WQ, WK, WV 모두 sharing하였을 때 ▶ All-Shared
세 가지로 나누어 실험을 수행하였다. 그 결과는 아래와 같다.
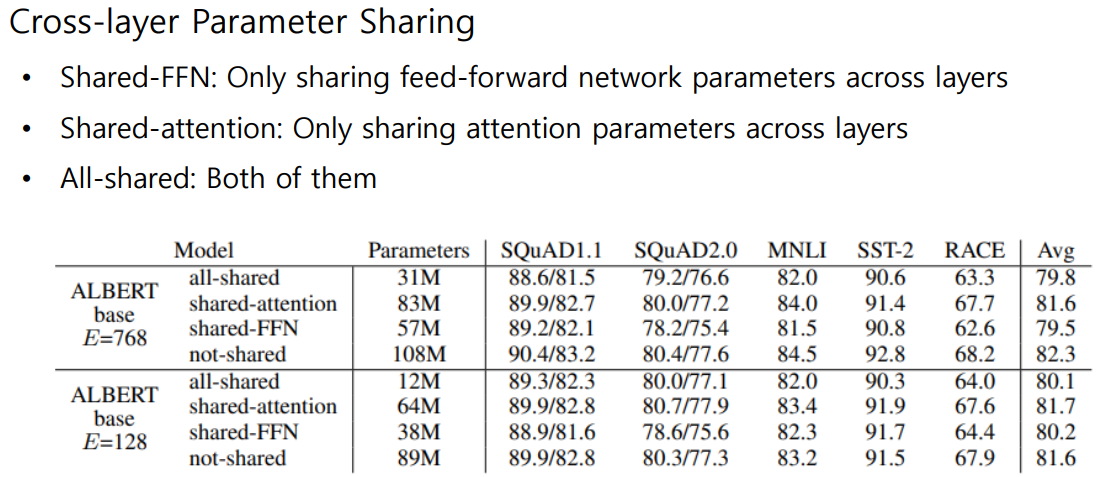
Parameter수가 가장 작은 All-shared를 보면, 기존의 BERT모델(=Not-shared)과 비교 했을 때 Parameter수는 대폭 줄었지만 성능의 하락폭은 작았다.
3. Sentence Order Prediction(SOP)
Sentence Order Prediction은 BERT의 두 task 중 Next Sentence Prediction을 더 발전시킨 것이다.
BERT에서 Masked Multi-Head Attention을 통해 다음에 올 단어를 예측하는 task가 하나 있었고, 또 다른 task로 두 문장을 하나의 sentence로 이어서 두 문장이 인접한지, 다음에 와도 되는 문장인지를 [CLS]토큰을 통해 분류하는 Binary-classification task(=Next Sentence Prediction, NSP)가 있었다. 그러나 NSP는 실용성이 없었으며, 심지어 [MASK]토큰으로 해당 task를 학습했을 때 오히려 더 좋은 결과를 내었다.
ALBERT는 두번째 task를 더 실용성 있게 개선하였다. 동일한 단어의 포함에 초점을 두어 두 문장이 인접한지를 판단하는 BERT의 NSP와 달리, 두 문장의 순서가 올바른지 혹은 잘못됐는지를 논리적으로 판단할 수 있도록 하였다.

그 결과, Sentence Prediction task에서 BERT의 [Mask]토큰 및 NSP로 학습한 모델과 ALBERT의 SOP으로 학습한 모델을 비교하였을 때, ALBERT의 SOP이 가장 뛰어난 성능을 나타냈다.
※ ALBERT의 GLUE 결과
다양한 NLP task를 benchmark dataset으로 포함하는 GLUE의 결과를 보면, 다양한 task에 대해 BERT, XLNet, RoBERT, ALBERT를 비교했을 때, ALBERT모델이 전체적으로 성능이 가장 좋은 것으로 나타났다.

ELECTRA
Masked Language Model(MLM)이 [MASK]토큰만 학습하는 비효율적인 문제를 보완하기 위해, ELECTRA가 GAN과 유사한 새로운 구조를 제안했다. [MASK]토큰을 예측하는 Generator를 거친 후(여기까지 BERT와 동일), 각 토큰에 대해 제공된 토큰인지 혹은 Generator로 예측한 토큰인지를 Discriminator로 판별한다.
※ 만약 Generator로 예측한 토큰이 정답과 같다면, 이때는 replaced가 아닌 original로 분류한다. (GAN과의 차이점)

MLM과 ELECTRA의 비교 실험 결과는 아래 그림과 같다. MLM은 연산이 증가할 수록 좋은 성능을 보인다. ELECTRA는 모든 경우 MLM의 성능을 능가하였다.

이외에도 자연어 생성 모델을 develop하려는 많은 연구가 있었는데, GPT-2, ELECTRA 등의 무거운 모델과 성능은 비슷하게 유지하되 GPU, 클라우드 없이 일반인 device에도 돌아갈 수 있을 만큼 모델을 경량화하는데 초점을 맞춘 Light-weight Model이 있다. Distillation기법을 사용한 두 논문을 보자.
Light-weight Model
Teacher Model, Student Model을 두어 Teacher 모델이 수행하는 것을 경량화된 Student 모델이 잘 모사할 수 있도록 학습을 진행하는 것을 Distillation이라 한다. Distillation기법을 사용한 두 논문을 보자.
■ DistillBERT는 Transformer의 구현체를 라이브러리 형식으로 자유롭게 사용할 수 있도록 배포한 것으로 유명한 Huggingface에서 발표한 논문이다. 다음에 올 단어를 예측할 때 score를 softmax에 적용하여 확률 분포를 얻고 Ground truth 확률 분포 대신 Teacher Model의 확률 분포를 softmax에 주어 예측값이 유사하도록 한다.
■ TinyBERT는 score의 확률 분포에 Teacher Model의 확률 분포를 줄 뿐만 아니라, Embedding Layer, WQ, WK, WV를 계산하는 Attention Matrix, 그 결과로 나오는 Hidden Layer의 parameter까지도 유사하도록 중간 결과물을 MSE를 통해 학습한다.

Fusing Knowledge graph into Language Model

[reference]
• How to Build OpenAI’s GPT-2: “ The AI That Was Too Dangerous to Release” https://blog.floydhub.com/gpt2/
• decaNLP https://decanlp.com/
• GPT-2 https://openai.com/blog/better-language-models/
• GPT-2 https://cdn.openai.com/better-languagemodels/language_models_are_unsupervised_multitask_learners.pdf
• Language Models are Few-shot Learners, NeurIPS’20 https://arxiv.org/abs/2005.14165
• Illustrated Transformer http://jalammar.github.io/illustrated-transformer/
• ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ICLR’20 https://arxiv.org/abs/1909.11942
• Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, JMLR’20 https://arxiv.org/abs/1910.10683
• ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators, ICLR’20 https://arxiv.org/abs/2003.10555
• DistillBERT, a distilled version of BERT: smaller, faster, cheaper and lighter https://arxiv.org/abs/1910.01108
• TinyBERT: Distilling BERT for Natural Language Understanding, Findings of EMNLP’20 https://arxiv.org/abs/1909.10351
• ERNIE: Enhanced Language Representation with Informative Entities https://arxiv.org/abs/1905.07129
• KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning https://arxiv.org/abs/1909.02151
'AI > 딥러닝' 카테고리의 다른 글
| [MRC] MRC 개념 / 종류 / 평가 방법 , Python Unicode , Tokenization , KorQuAD (0) | 2021.10.13 |
|---|---|
| [특강] AI 서비스 개발 및 AI 기술팀 조직 구성 (0) | 2021.09.27 |
| [NLP] GPT-1 , BERT (0) | 2021.09.19 |
| [NLP] Transformer (0) | 2021.09.19 |
| [NLP] Beam search decoding , BLEU score (2) | 2021.09.12 |




댓글