기계독해, Machine Reading Comprehension(MRC)란 주어진 지문(Context)을 이해하고, 주어진 질의(Query/Question)의 답변(Answer)을 추론하는 문제이다.
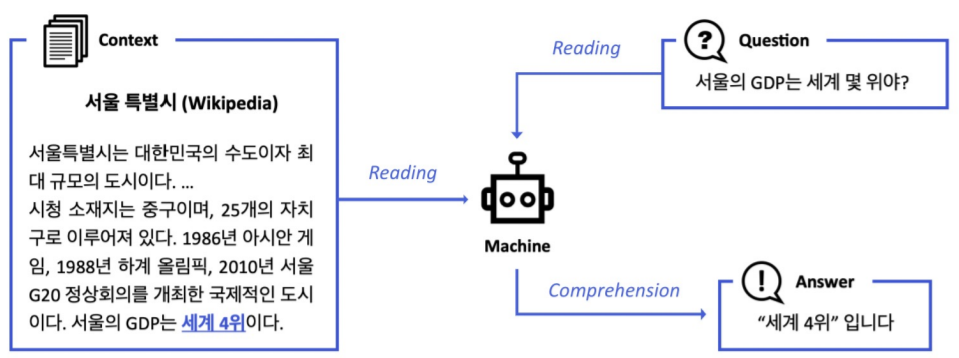
이번 포스팅에서는 특정 지문이 주어졌다는 가정 하에 질문에 답변하는 모델을 살펴보고, 다음 포스팅에서 위키피디아 전체에서 질문에 대한 답변을 어떻게 하는지 알아볼 것이다.
MRC 개념
MRC는 Query에 대한 정보가 담긴 지문을 찾은 후(Retrieval), 그 지문을 세밀히 읽어서(Read) 답변을 찾는다. 따라서 크게 Retrieval과 Read로 나뉘며 이러한 기법은 Search engine 및 Dialogue system에서도 사용된다.

MRC 종류
1. Extractive Answer Datasets
질의에 대한 답변이 주어진 지문의 segment(or span)로 존재
· 관련 Dataset : SQuAD, KorQuAD, NewsQA, Natural Question

2. Descriptive/Narrative Answer Datasets
지문 내에서 답변을 추출하지 않고, 질의에 맞게 sentence(or free-form)생성
· 관련 Dataset : MS MARCO, Narrative QA

3. Multiple-choice Datasets
질의에 대한 답변을 여러 개의 answer candidates중 하나로 고르는 형태
· 관련 Dataset : MCTest, RACE, ARC

MRC challenge
1. 동일한 의미를 지녔으나 다른 단어들로 구성된 문장 이해 (Paraphrasing)

2. Unanswerable questions

3. Multi-hop reasoning : 여러 개의 document에서 질의에 대한 supporting fact를 찾아야지만 답을 찾을 수 있음

MRC 평가방법
1. Exact Match / F1 Score
Ground-truth와 얼마나 일치하는 지를 측정하므로 extractive answer 및 multiple-choice answer dataset에 적합한 평가

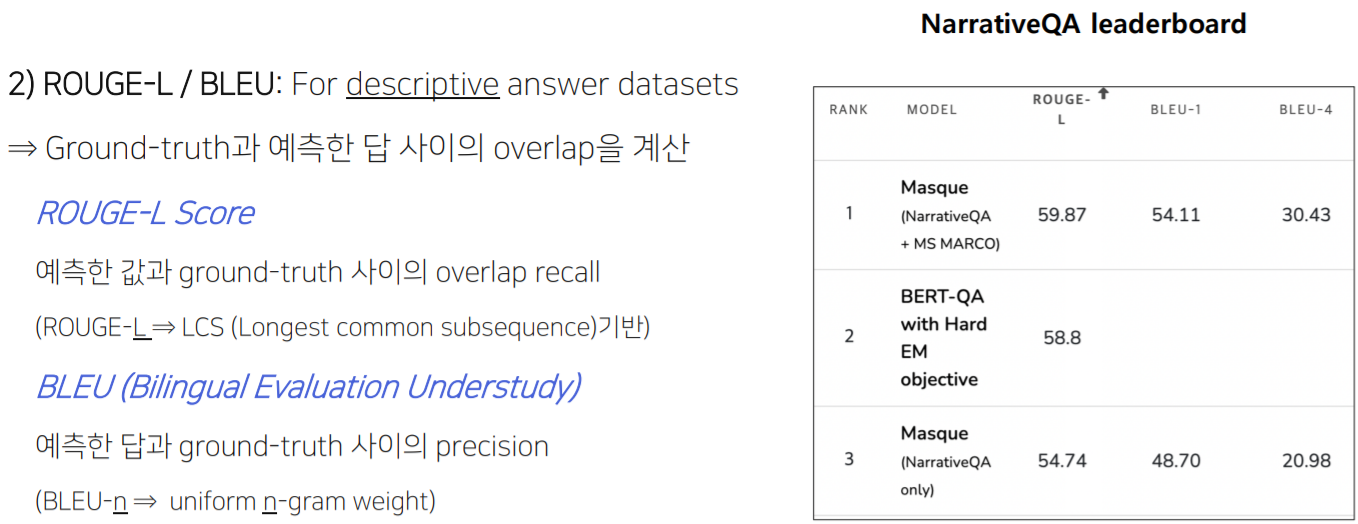
2. ROUGE-L / BLEU
Ground-truth와 얼마나 overlap이 있는 지를 측정하며, 답변을 새로이 생성해내는 descriptive answer dataset에 적합한 평가
Unicode
유니코드란 전 세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋이며, 각 문자마다 숫자 하나에 매핑된다.

■ 인코딩 & UTF-8

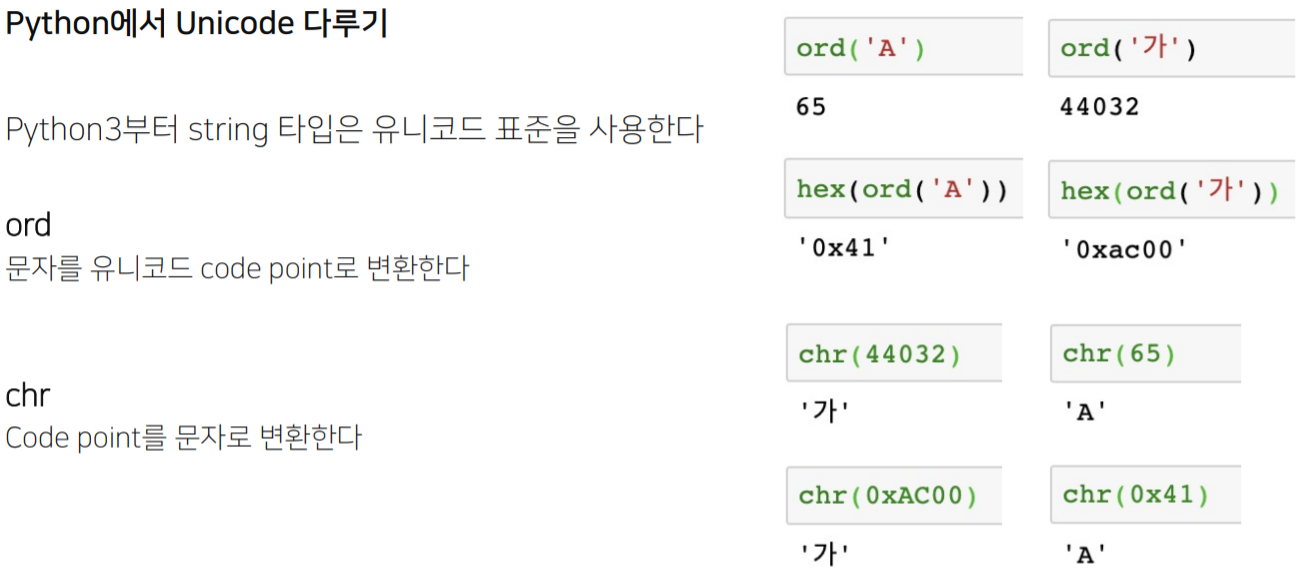
■ 파이썬으로 Unicode확인
ord를 통해 아스키코드를 알 수 있다. 반대로 chr를 사용하면 아스키코드에 대한 문자를 확인할 수 있다.
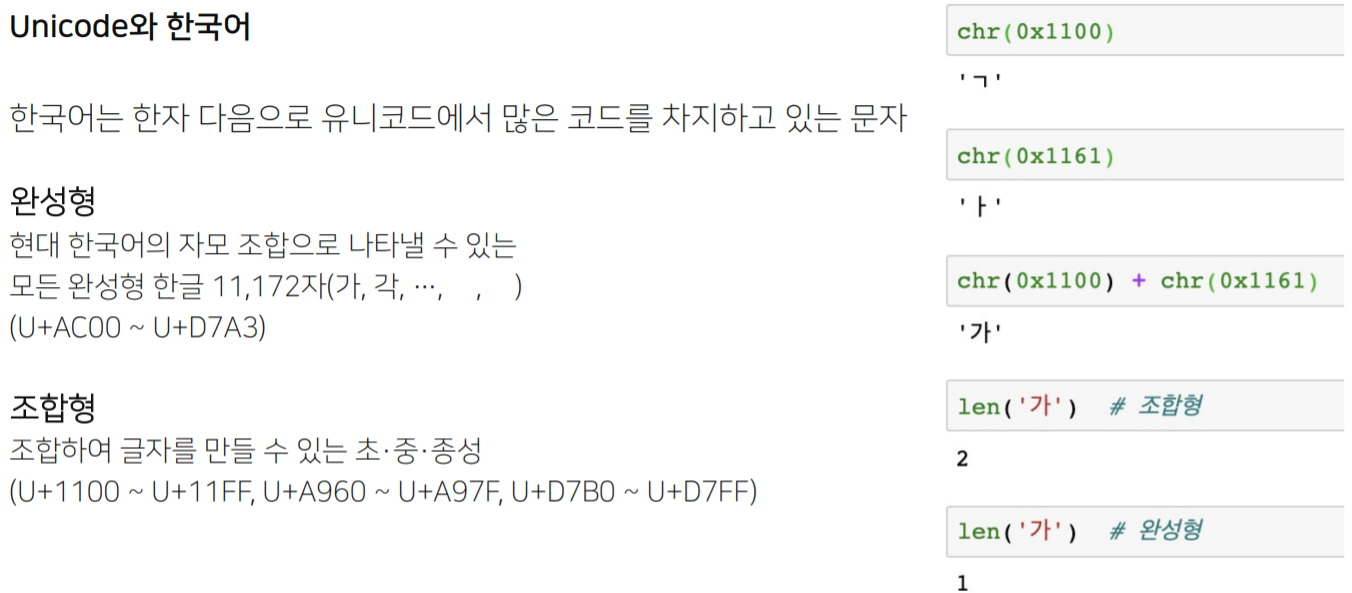
■ 한국어 Unicode
'가'의 경우 완성형은 하나의 Unicode로 이루어져 len=1이지만, 조합형은 'ㄱ', 'ㅏ' 두 가지 Unicode로 조합되어 len=2이다.
Tokenization
토크나이징이란 텍스트를 토큰 단위로 나누는 것을 말한다. 단위는 단어(띄어쓰기 기준), 형태소, subword 등 여러가지가 가 사용된다.
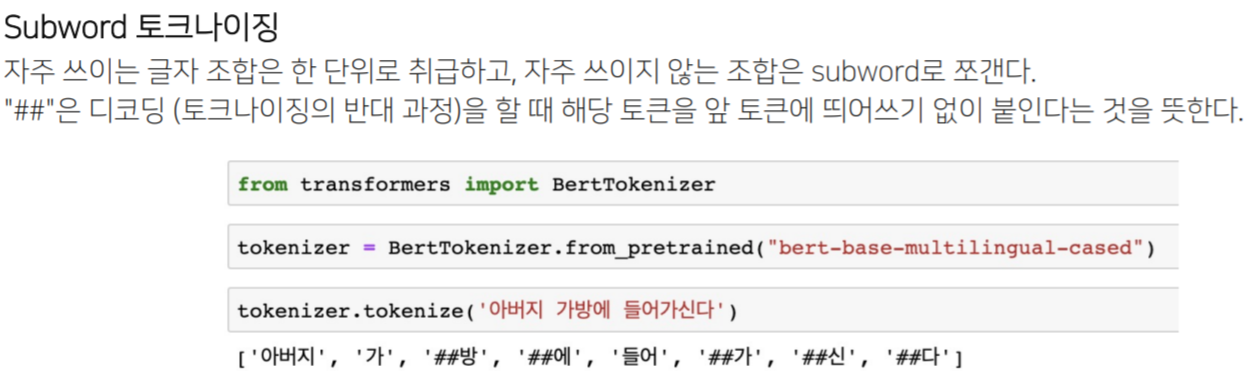
■ Subword
많은 단어를 학습시킬지라도 모르는 단어는 또 등장하기 마련이다. 이를 OOV(Out-Of-Vocabulary) 또는 UNK(Unknown Token)으로 표시하고 이를 OOV문제라 한다. '먹었다', '먹으니'와 같이 '먹'이라는 어근과 '었다'라는 어미를 분리하는 등 하나의 단어를 더 잘게 쪼갤 수 있다. 이렇게 더 잘게 쪼개어 인코딩하는 것을 Subword tokenizing이라 한다.
※ Subword토크나이징은 ##을 사용하여 독립적인 단어(띄어쓰기 기준)가 아님을 표시한다.
■ BPE
BPE는 대표적인 Subword tokenizing방법이다. BPE는 연속적으로 글자의 쌍이 가장 많은 것을 찾아 하나의 글자로 치환하는 방식이다.

※ 참고 https://wikidocs.net/22592
KorQuAD
KorQuAD란,

※ 참고 https://korquad.github.io/
■ KorQuAD 데이터 수집 과정
SQuAD v1.0의 데이터 수집 방식을 벤치마크하였다.

■ HuggingFace Dataset 라이브러리
아래 두 줄로 HuggingFace에서 squad_kor_v1, squad_kor_v2를 통해 KorQuAD 데이터셋을 불러올 수 있다. HuggingFace에서 불러온 데이터셋은 memory-mapped, cached되어 있으므로 data load시 생기는 메모리 부족 혹은 전처리 과정의 반복을 피할 수 있다.
from datasets import load_dataset
dataset = load_dataset('squad_kor_v1', split='train')
■ KorQuAD 예시

■ KorQuAD 데이터 출력 형태

■ KorQuAD 질문 유형
구문변형, 유의어, 일반상식, 여러 문장의 근거 활용, 논리적 추론, 오류에 대한 질문이 존재하며, 비교적 추론하기 쉬운 구문변형이 가장 많다.

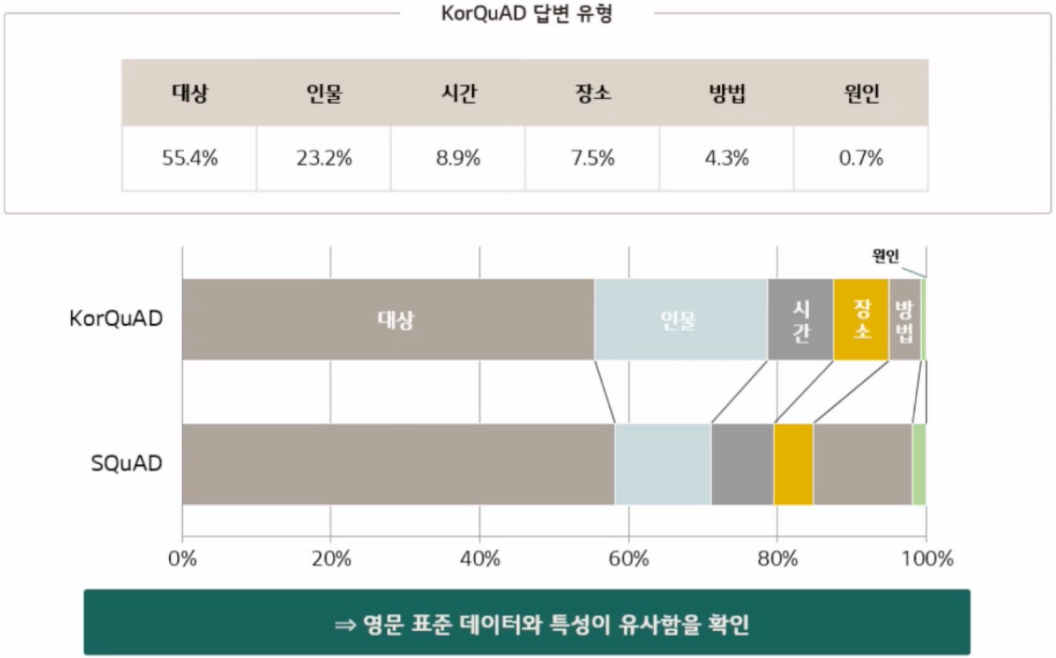
■ KorQuAD 답변 유형
답변 유형으로는 대상(무엇을), 인물(누가), 시간(언제), 장소(어디서), 방법(어떻게), 원인(왜)이 있으며, 육하원칙 안에서 답변이 도출된다.
[reference]

'AI > 딥러닝' 카테고리의 다른 글
| [MRC] Generation-based MRC (0) | 2021.10.13 |
|---|---|
| [MRC] Extraction-based MRC (0) | 2021.10.13 |
| [특강] AI 서비스 개발 및 AI 기술팀 조직 구성 (0) | 2021.09.27 |
| [NLP] GPT-2 , GPT-3 , ALBERT , ELECTRA (0) | 2021.09.21 |
| [NLP] GPT-1 , BERT (0) | 2021.09.19 |




댓글