오늘 소개할 BERT와 GPT-1(자연어 생성모델)는 모두 Transformer에 기반을 두고 있기 때문에, 만약 Transformer에 대해 잘 모른다면 아래 링크에서 Transformer를 먼저 학습해주세요!
https://amber-chaeeunk.tistory.com/96
[NLP] Transformer
※ 이 글은 KAIST 주재걸 교수님의 강의 내용 및 자료를 바탕으로 작성합니다. 오늘은 Recurrent 모델을 사용하지 않고, Attention으로만 encoder와 decoder를 설계한 Transformer에 대해 다룰 것이다. 먼저 RNN
amber-chaeeunk.tistory.com
GPT-1과 BERT는 모두 Self-supervised Pre-training Model이다. 즉, label없이 self-supervised learning된 모델을 Transfering한 후, task에 맞게 Fine-tuning하기 위해 사용할 때의 그 pre- training model이다.

(참고) Unsupervised Learning & Self-supervised Learing:
https://www.facebook.com/722677142/posts/10155934004262143/
GPT-1
GPT-1은 테슬라 창업자 Elon Musk가 세운 비영리 연구기관 Open AI에서 나온 모델로 Transformer의 Decoder를 사용하여 만들어졌다.
GPT-1은 <S>, <E>, $와 같은 special token을 도입하여 classification, entailment, similarity, multiple choice와 같은 다양한 task를 통합적으로 수행할 수 있는 모델을 제안했다.
어떤 단어를 input으로 넣으면 그 다음에 올 단어를 예측하는 Language Model뿐만 아니라, Sentence가 긍정인지 부정인지 분류하는 task도 동시에 수행할 수 있다. 이처럼 단어단위의 task외에 문장단위의 task도 수행할 수 있다.
pre-training 모델의 경우, label이 없는 self-supervised learning을 수행하고, fine-tuning 모델의 경우, 수행하고자 하는 task에 따른 label이 있어야 한다.
아래 그림은 수행하고자 하는 task만을 위한 customized모델과 self-supervised learning한 pre-training모델을 Transfer learning한 GPT-1모델을 비교하였을 때, GPT-1이 성능이 뛰어난 것을 보여주는 표이다.
BERT
BERT도 GPT-1과 마찬가지로 다음에 올 단어를 예측하는 language model이며, GPT-1보다 더 높은 성능을 자랑하며 등장하였다. BERT는 Transformer의 Encoder를 사용하여 만들어졌다. (Transformer의 Encoder를 사용하였는데 어떻게 다음에 올 단어를 예측할 수 있는지에 대한 궁금증을 가지고 계속 읽어보자! 그것이 바로 BERT의 핵심이다.)
BERT와 GPT-1이 등장하기 전에, LSTM으로 다음 단어를 예측하는 language model이 있었는데, 아래 그림의 오른쪽에 있는 ELMo이다. 이후 LSTM의 encoding방식을 모두 Transformer의 방식으로 대체한 GPT-1과 BERT모델이 나와 많은 양의 데이터도 학습을 잘 할 수 있도록 발전되었다.
다음으로 BERT의 Motivaton을 살펴보자. GPT-1의 경우 <sos> I study 와 같이 <sos>토큰이 입력되면 I를 예측하고, I가 입력되면 study를 예측하는데, 이는 단어를 예측할 때 이전의 문맥만 고려하고 다음에 오는 단어들은 전혀 고려하지 않는다. 그러나 이전의 문맥을 놓치더라도 다음에 오는 문맥을 캐치하면 과거의 문맥을 추론할 수 있다.
이러한 문제를 개선하기 위해 BERT는 Masked Language Model을 제안하였다. Transformer의 Encoder를 사용하면서 다음 단어를 예측하는 Language Model을 만들 수 있었던 이유가 바로 "Masked"이다. ★Encoder에 input을 넣을 때 부터 문장 내 15%의 token을 Mask처리한다. 이 15%의 token 중 80%는 [MASK] token으로 대체하고, 10%는 아무 단어로 대체하여 틀린 단어에 대해서 수정할 수 있도록 유도하였고, 나머지 10%는 원래의 정답 token으로 하여 맞는 단어에 대해 소신있게 유지할 수 있도록 하였다.
BERT는 GPT-1처럼 단어 단위의 예측 이외에 문장 단위의 task를 수행할 수 있는 Next Sentence Prediction기법도 제안하였다.
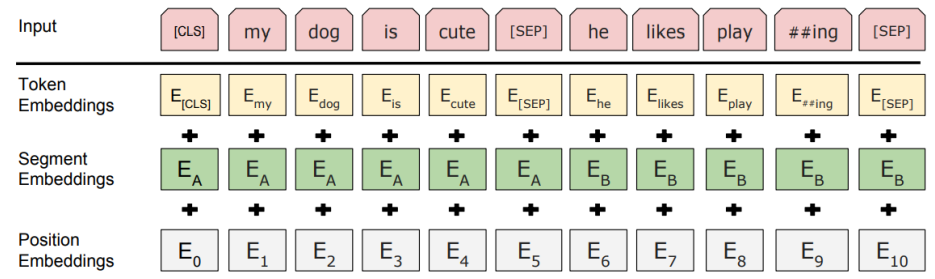
아래 그림처럼 두 문장이 있을 때, 각 문장 끝에 [SEP] token으로 문장을 구분하고 [CLS] token을 통해 이 문장이 연달아 와도 되는 문장인지 아닌지를 Binary-Classification한다. 두 문장이 인접하다면 IsNext라는 label로, 인접하지 않다면 NotNext로 분류된다.

아래 그림을 보며 BERT모델을 요약해보자.
※ L = Layer 개수, A = Multi-Head 개수, H = Encoding vector dimension

2번 항목인 Input Representation에 대해 추가적으로 언급하자면,
- Input vector는 word 단위를 token으로 하지 않고, WordPiece를 사용하여 word를 더 잘게 쪼갠 sub-word들을 token으로 하여 encoding한 것이다.
- Learned positional embedding은 transformer에서 sin, cos함수로부터 사전에 정의된 값으로 positional encoding vector를 사용한 것과 달리 training을 통해 최적의 vector를 찾는 것이다.
- [CLS], [SEP] 토큰을 사용하였다.
- segment embedding이 추가되는데, 이유는 문장단위의 task에서 문장 간 구분 없이 positional embedding이 되지 않도록 새로 시작하는 문장을 구분하기 위함이다. (ex. 아래 그림에서 E6은 두번째 문장의 첫번째 position)
Fine Tuning 구조
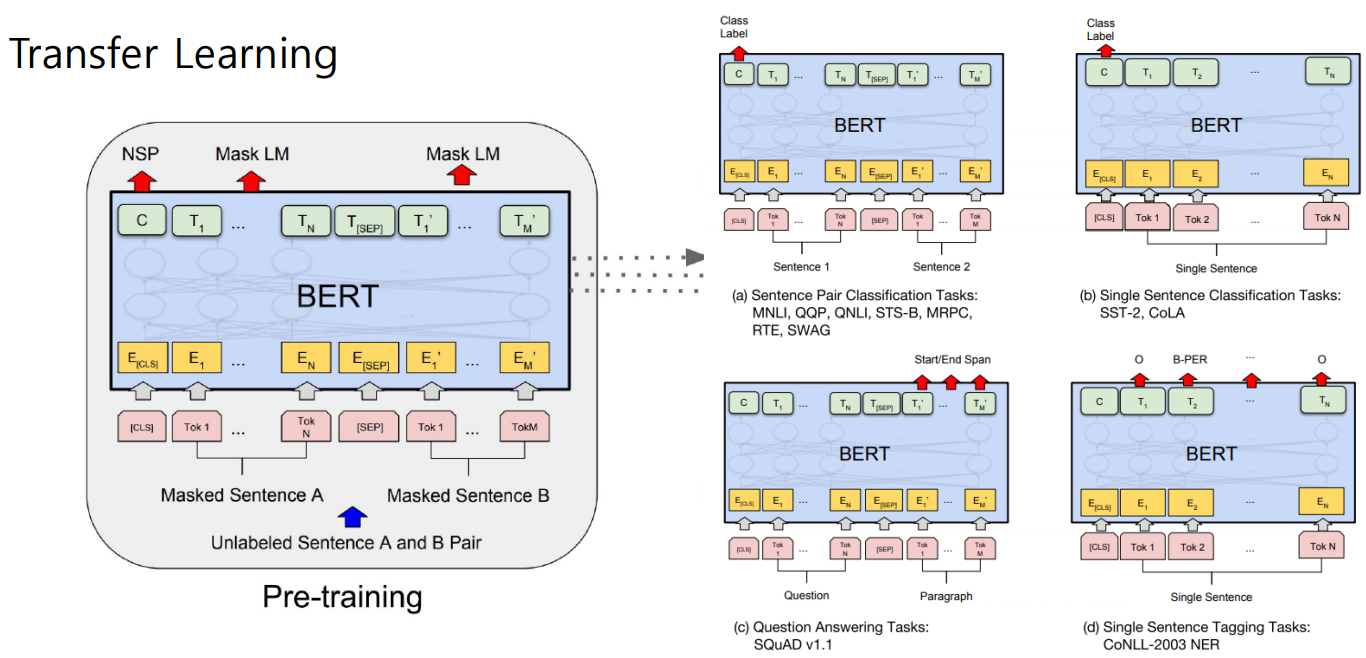
GPT-1과 BERT 비교

NLP관련 여러가지 task를 수행했을 때 BERT가 뛰어난 성능을 보였다. 참고로 여러가지 task를 모아놓은 benchmark dataset을 GLUE라고 한다.
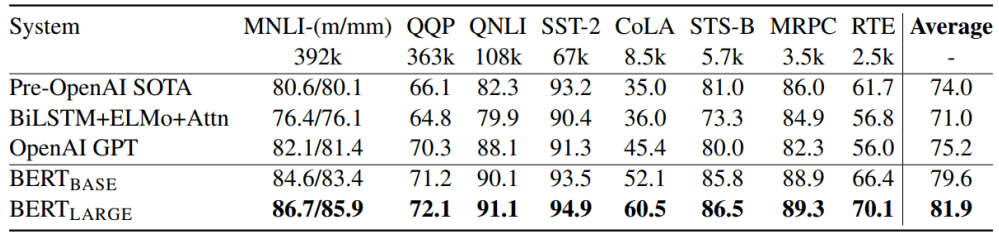
Fine-tuning for MRC task
추가로 BERT모델을 Fine-tuning하여 높은 성능을 얻을 수 있는 MRC(Machine Reading Comprehension) task를 살펴보자.
Question에 대한 Answer을 제공하기 위해 어떤 문서에서 글을 읽고 답변을 찾아서 제공한다.

※ MRC에 대한 대표적인 데이터로는 위키피디아 기반의 SQuAD가 있다. 버전1.1은 <sos>, <eos>토큰을 사용하여 특정 위치의 답을 예측하는 것이고, 버전2.0은 [CLS]토큰을 사용하여 두 문장이 인접한지 학습하여 질문 문장에 대한 답이 해당 문장에 있는지를 분류한다.
※ 질문 문장에 대해 4개의 보기 문장에서 정답을 찾는 SWAG라는 데이터셋도 있다.
[reference]
• GPT-1 https://blog.openai.com/language-unsupervised/
• BERT : Pre-training of deep bidirectional transformers for language understanding, NAACL’19 https://arxiv.org/abs/1810.04805
• SQuAD: Stanford Question Answering Dataset https://rajpurkar.github.io/SQuAD-explorer/
• SWAG: A Large-scale Adversarial Dataset for Grounded Commonsense Inference https://leaderboard.allenai.org/swag/submissions/public
• https://ratsgo.github.io/nlpbook/docs/language_model/bert_gpt/
'AI > 딥러닝' 카테고리의 다른 글
| [특강] AI 서비스 개발 및 AI 기술팀 조직 구성 (0) | 2021.09.27 |
|---|---|
| [NLP] GPT-2 , GPT-3 , ALBERT , ELECTRA (0) | 2021.09.21 |
| [NLP] Transformer (0) | 2021.09.19 |
| [NLP] Beam search decoding , BLEU score (2) | 2021.09.12 |
| [NLP] Seq2seq with Attention (0) | 2021.09.10 |




댓글