오늘은 Modeling하기 전 단계인 Data Processing에서 할 수 있는 간단한 스킬을 알아볼 것이다.

이미지 데이터의 경우, 파라미터 수를 조정하기 위해 데이터를 resize하거나 over-fitting을 방지하기 위한 작업으로 이미지를 회전하거나 자르거나 noise를 추가하거나 색상을 변경하는 등의 augmentation기법을 주로 사용한다. 아래에서 하나씩 살펴보자.
■ Bounding box
Bounding box는 불필요한 정보로부터 중요한 정보를 추출하기 위한 작업이다.

■ Resize
데이터의 size가 클 경우, parameter수가 많아지므로 resize를 통해 적절한 size로 조정할 수 있다.

■ Data Augmentation
Data에 noise를 추가함으로써 over-fitting을 줄이는 기법이다. 아무 기법이나 적용한다고 성능이 오르지 않는다. Problem Definition에 대한 이해를 바탕으로 적절한 augmentation을 적용할 수 있어야 한다. 아래 그림을 보면, 자동차는 야간 주행을 하거나 폭우 속에서 주행을 할 상황에 놓일 수 있으며, 그러한 상황에서도 잘 구분해야하기 때문에 적절한 augmentation을 적용했다고 볼 수 있다.

■ [example] Blindness detection
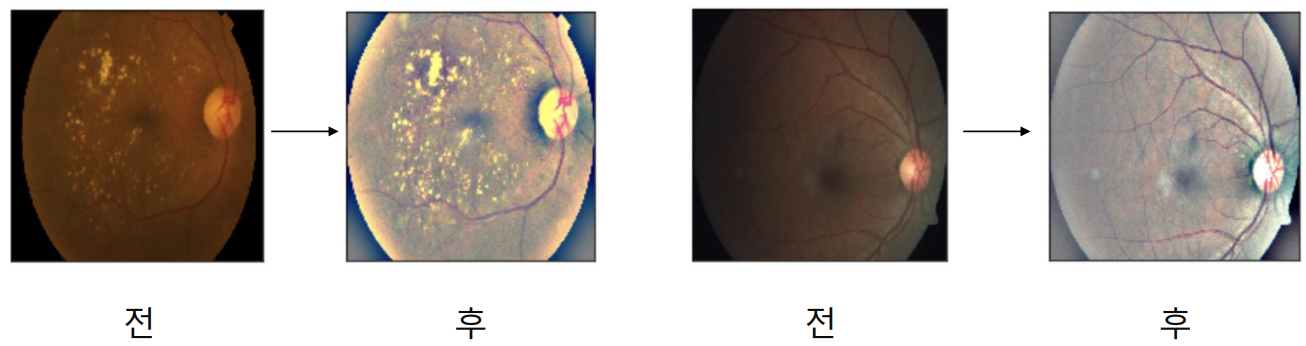
아래 예시는 blindness를 잘 detect하기 위해 그 특징을 두드러지게 나타낼 수 있도록 밝기를 높인 것이다. 안구에 있는 손상된 형태들을 잘 발견해내야 하는 Problem Definition에 기반하여 적절한 transform을 적용하였다.
■ Image pre-processing에 적용할 수 있는 함수들
· torchvision.transforms


· Albumentations
Albumentations는 다양한 augmentation을 위한 라이브러리이다. torchvision에서 제공하는 기법들보다 더 다양하고 많은 것을 제공한다.


[github] https://github.com/albumentations-team/albumentations
GitHub - albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries.
Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 -...
github.com
■ Data Feeding
Data를 Model에 feeding할 때 주의해야할 점은 '효율'이다. 아래의 그림을 보자. 만약 모델이 초당 20batch를 처리할 수 있는데, Data Generator가 초당 10batch밖에 생성하지 못한다면 모델이 가지는 효율을 온전히 활용하지 못할 것이다. 반대로 Data Generator가 초당 30batch를 처리할 수 있지만 Model이 초당 20batch밖에 처리하지 못한다면 아무리 데이터를 효율적으로 넘겨주어도 그것을 소화해내지 못할 것이다. 따라서 데이터 잘 가공하는 것 뿐만 아니라 잘 출력해낼 수 있도록 만들어야 한다.

아래 그림은 세 개의 Dataset으로부터 데이터를 뽑아내는 속도를 실험한 결과이다. 왼쪽 transform에 포함된 여러 기법들의 순서를 유심히 보고 세 가지 속도를 비교해보자.

왼쪽의 transform에 있는 resize와 RandomRotation의 순서에 따라 속도에 차이가 있는 모습을 볼 수 있다. 첫번째와 달리 두번째에서는 데이터 사이즈를 1024로 매우 크게 resize하여 속도가 느려졌다. 두번째와 달리 세번째에서는 데이터 사이즈를 매우 크게 만든 후에 RandomRotation을 적용했기 때문에 속도가 더 느려졌다.
결론은 이처럼 transform의 순서와 같은 단순한 작업에서도 속도를 고려하여 구성함으로써 Data Generation 효율에 신경을 써야한다는 것이다.
이제 위에서 배운 여러가지 기법들을 포함할 Dataset과 DataLoader클래스를 살펴볼 것이다.
■ torch.utils.data
· Dataset
먼저 Dataset클래스를 보자. Dataset클래스는 Vanila data를 원하는 형태로 출력하는 클래스이다. 기본 구조로 __init__, __getitem__, __len__ 세 가지 부분으로 구성된다.


· DataLoader
DataLoader은 Dataset을 효율적으로 사용할 수 있도록 여러가지 기능을 추가한 클래스이다.

DataLoader를 통해 batch, augmentation, tensor 등의 작업을 추가할 수 있다.

예를 들어, Data loading시 사용되는 subprocess개수를 의미하는 num_workers를 2 → 3으로 올렸을 때, 속도가 향상되는 것을 볼 수 있다.

※ 원하는 형식으로 출력하도록 하는 Dataset과 Dataset을 효율적으로 사용하도록 하는 DataLoader는 서로 다른 기능을 가지기 때문에 개별적으로 클래스를 생성하는 것이 좋다.
'AI > 딥러닝' 카테고리의 다른 글
| [NLP] NLP Tasks , Bag of Words , Word Embedding , GloVe (0) | 2021.09.09 |
|---|---|
| [이미지 분류] Modeling (0) | 2021.08.27 |
| [Pytorch] Dataset , DataLoader (0) | 2021.08.22 |
| [Pytorch] Hyper-parameter Tuning , Pytorch Troubleshooting (0) | 2021.08.21 |
| [Pytorch] Multi-GPU (0) | 2021.08.21 |




댓글