1. Hyper-parameter Tuning
모델의 성능이 잘 안 나오면 보통 모델을 바꾸거나, 데이터를 바꾸거나, Hyper-parameter를 Tuning한다. 이 중 성능 향상에 큰 기여는 하지 않지만 좋은 데이터와 모델을 통해 어느 정도 성능을 갖추었을 때 미세하게 성능 향상을 할 수 있는 Hyper-parameter Tuning에 대해 알아보자.
■ Hyper-parameter Search
Hyper-parameter를 탐색하는 가장 기본적인 방법에는 grid search와 random search가 있다. 아래 그림에서 왼쪽은 grid search를 나타내고 오른쪽은 random search를 나타낸다.
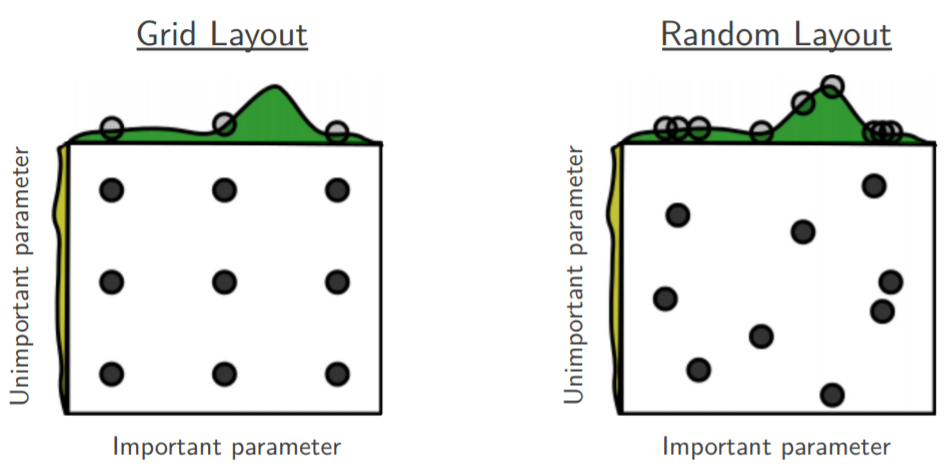
Grid search를 예를 들면, learning rate를 가로축으로 하여 0.1 0.01 0.001 ··· 로 두고, batch size를 세로축으로 하여 32, 64, 128 ··· 로 두어 차례대로 학습을 수행하는 것이다. 반면 Random search는 일정하게 값을 찾지 않고 무작위로 학습하여 가장 좋은 것을 취하는 방식이다.,
최근에는 단순한 Grid search나 Random search보다 베이지안 기반의 기법을 많이 사용한다.
[BOHB 레퍼런스]
- https://arxiv.org/pdf/1807.01774.pdf
- https://www.automl.org/blog_bohb/
AutoML | BOHB: Robust and Efficient Hyperparameter Optimization at Scale
By André Biedenkapp, Frank Hutter Machine learning has achieved many successes in a wide range of application areas, but more often than not, these strongly rely on choosing the correct values for many hyperparameters (see e.g. Snoek et al., 2012). For ex
www.automl.org
■ Hyper-parameter 조정을 위한 도구 : Ray
· multi-node, multi-processing 지원 모듈
· ML/DL 병렬 처리를 위한 모듈
· 분산병렬 ML/DL 모듈의 표준
· Hyperparameter Search를 위한 다양한 모듈 제공
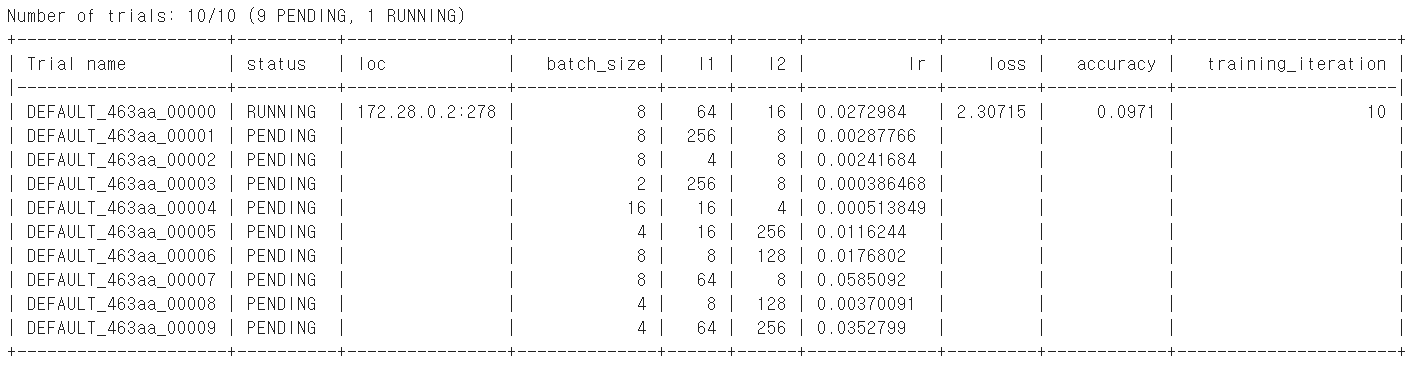
※ Ray로 최적의 Hyper-parameter 찾는 부분 코드
from ray.tune.suggest.bayesopt import BayesOptSearch from ray.tune.suggest.hyperopt import HyperOptSearch def main(num_samples=10, max_num_epochs=10, gpus_per_trial=2): data_dir = os.path.abspath("./data") load_data(data_dir) #congif에 search space지정(grid search 방법 사용) config = { "l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)), "l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)), "lr": tune.loguniform(1e-4, 1e-1), "batch_size": tune.choice([2, 4, 8, 16]) } #스케줄러 알고리즘 지정 scheduler = ASHAScheduler( metric="loss", mode="min", max_t=max_num_epochs, grace_period=1, reduction_factor=2) reporter = CLIReporter( # parameter_columns=["l1", "l2", "lr", "batch_size"], metric_columns=["loss", "accuracy", "training_iteration"]) result = tune.run( partial(train_cifar, data_dir=data_dir), resources_per_trial={"cpu": 2, "gpu": gpus_per_trial}, config=config, num_samples=num_samples, scheduler=scheduler, progress_reporter=reporter) #가장 성능이 좋은 trial 저장 best_trial = result.get_best_trial("loss", "min", "last") print("Best trial config: {}".format(best_trial.config)) print("Best trial final validation loss: {}".format( best_trial.last_result["loss"])) print("Best trial final validation accuracy: {}".format( best_trial.last_result["accuracy"])) #가장 좋은 parameter를 설정하여 model재설정 best_trained_model = Net(best_trial.config["l1"], best_trial.config["l2"]) device = "cpu" if torch.cuda.is_available(): device = "cuda:0" if gpus_per_trial > 1: best_trained_model = nn.DataParallel(best_trained_model) best_trained_model.to(device) best_checkpoint_dir = best_trial.checkpoint.value model_state, optimizer_state = torch.load(os.path.join( best_checkpoint_dir, "checkpoint")) best_trained_model.load_state_dict(model_state) test_acc = test_accuracy(best_trained_model, device) print("Best trial test set accuracy: {}".format(test_acc)) if __name__ == "__main__": # You can change the number of GPUs per trial here: wandb.login(key="0a25ae829bf4e2a6cd2acfdd4e65e6a26cd9927e") main(num_samples=10, max_num_epochs=10, gpus_per_trial=0)
2. Pytorch Troubleshooting
딥러닝 학습에 있어서 가장 많이 발생하는 오류는 Out Of Memory(OOM)이다. 보통 OOM이 발생하면 batch size를 줄이거나 GPU를 비우는데 아래에서 Troubleshooting을 할 수 있는 방법을 몇 가지 알아보자.
■ Troubleshooting 방법 1 : GPUUtill 사용
- nvidia-smi같은 GPU 상태 보여주는 모듈
- Colab은 환경에서 GPU 상태 보여주기 편함
- iter마다 메모리가 늘어나는지 확인 가능
!pip install GPUtil import GPUtil GPUtil.showUtilization()
■ Troubleshooting 방법 2 : torch.cuda.empty_cache() 사용
- 사용되지 않는 GPU의 cache를 정리
- 가용 메모리 확보
- del 과 구분 필요
- reset 대신 쓰기 좋은 함수
- 파라미터 학습하는 반복문 전에 한 줄 써주기
■ Troubleshooting 방법 3 : training loop에 tensor로 축적되는 변수 확인
- Tensor 변수는 GPU상의 메모리 사용
- Loop안에 tensor변수의 연산이 있을 때 GPU에 computational graph 생성하여 메모리를 잠식함
- 따라서 1-d tensor경우 python 기본 객체로 변환하여 처리 (.item 또는 float()을 붙이면 python 기본 객체로 반환)
■ Troubleshooting 방법 4 : del 명령어 적절히 사용
- 필요 없어진 변수는 적절한 삭제 필요
- Python의 메모리 배치 특성상 loop이 끝나도 메모리 차지
■ Troubleshooting 방법 5 : torch.no_grad() 사용
- Inference할 때는 torch.no_grad() 구문 사용
- Backward pass로 인해 쌓이는 메모리에서 자유로움
■ 그 이외의 Troubleshooting 방법들
- Colab에서 너무 큰 사이즈 실행하지 말 것 (CNN, LSTM, Linear)
- CNN의 대부분 에러는 크기가 안 맞아서 생기는 것이므로 torchsummary 등으로 사이즈 조정하기
- tensor의 float precision을 16bit로 줄일 수 있음
'AI > 딥러닝' 카테고리의 다른 글
| [이미지 분류] Data Processing (0) | 2021.08.24 |
|---|---|
| [Pytorch] Dataset , DataLoader (0) | 2021.08.22 |
| [Pytorch] Multi-GPU (0) | 2021.08.21 |
| [Optimization] Generalization , Under-fitting vs Over-fitting , Cross Validation (0) | 2021.08.16 |
| weight를 갱신할 때 기울기에 왜 Learning rate를 곱할까? (2) | 2021.08.15 |




댓글