이번 포스팅에서는 weight 업데이트에 사용되는 경사하강법에 대해 정리할 것이다. weight를 조정하는 방법을 설명하기 위해 가장 먼저 미분부터 살펴본다. 그 이유는 기울기를 알면 변수를 어느 방향으로 움직여야 함숫값이 증가하는지 감소하는지를 알 수 있기 때문이다. 그 후 변수가 벡터인 경우의 기울기를 나타내는 gradient vector를 다룰 것이다.
1. 미분(differentiation)

미분은 함수 f의 주어진 점 (x, f(x))에서의 접선의 기울기이다.
※ 파이썬에서 미분은 sym.diff함수를 사용하여 계산할 수 있다.
import sympy as sym
from sympy.abc import x
sym.diff(sym.poly(x**2 + 2*x + 3), x) #poly(2*x + 2, x, domain='zz')
■ 목적함수 최대화 (경사상승법)
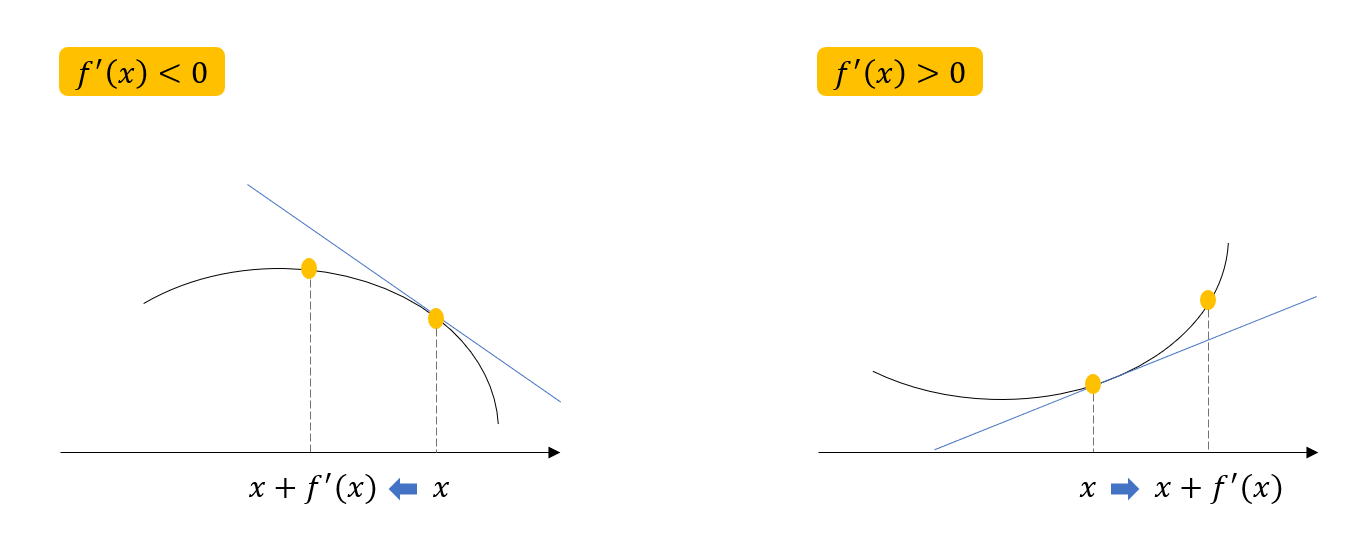
함숫값을 높이기 위해서는 미분값이 양수이든 음수이든 현재의 위치에서 미분값을 더하면 된다. 이는 목적함수를 최대화할 때 사용한다.
■ 목적함수 최소화 (경사하강법)

함숫값을 줄이기 위해서는 미분값이 양수이든 음수이든 현재의 위치에서 미분값을 빼주면 된다. 이는 목적함수를 최소화할 때 사용한다.
2. 경사하강법
Loss함수를 최소화하기 위해서는 경사하강법을 이용하여 weight를 갱신할 수 있다. 경사하강법은 weight의 기울기를 이용하여 함숫값이 낮아지는 방향으로 weight를 이동시켜 극값에 도달할 때까지 반복하는 것이다.

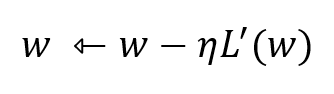
경사하강법을 통해 도달한 극값은 항상 최솟값을 보장하지는 않는다.
※ python 코드
def fun(val):
fun = sym.poly(x**2 + 2*x + 3)
return fun.sub(x, val), fun #fun.subs는 val을 fun의 x에 대입한 값
def func_gradient(fun, val):
_, function = fun(val)
diff = sym.diff(function, x) #fuction을 x에 대해 미분하는 코드
return diff.subs(x, val), diff
def gradient_descent(fun, init_point, lr_rate=1e-2, epsilon=1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, val)
while np.abs(diff) > epsilon:
val = val - lr_rate*diff
diff, _ = func_gradient(fun, val)
cnt += 1
print('함수: {}, 연산횟수: {}, 최소점: ({}, {})'.format(fun(val)[1], cnt, val, fun(val)[0]))
gradient_descent(fun=func, init_point=np.random.uniform(-2,2))
#함수: poly(x**2 + 2*x + 3, x, domain='zz'), 연산횟수: 646, 최소점: (-0.999995047967832, 2.00000000002452)
3. gradient vector
■ 편미분(partial differentiation)
변수가 벡터인 다변량 함수의 경우 편미분(partial differentiation)을 사용하여 기울기를 계산한다.

아래의 예시와 같이 x, y 두 변수 중 x에 대해서 편미분하는 것은 x방향의 움직임만 분석한다는 것이다.

※ 편미분 계산도 미분과 마찬가지로 파이썬에서 sym.diff함수를 이용하여 할 수 있다.
import sympy as sym
from sympy.abc import x, y
sym.diff(sym.poly(x**2 + 2*x*y + 3) + sym.cos(x + 2*y), x) #2*x + 2*y - sin(x + 2*y)
■ gradient vector
gradient vector는 변수 d개에 대해 각각 편미분 한 것을 한 번에 표시한다.

저 역삼각형 기호는 nabla라고 하며 gradient vector임을 나타내는 기호이다. f'(x) 대신 nabla를 사용하여 변수 x=(x1, x2, ···, xd)를 동시에 update할 수 있다.
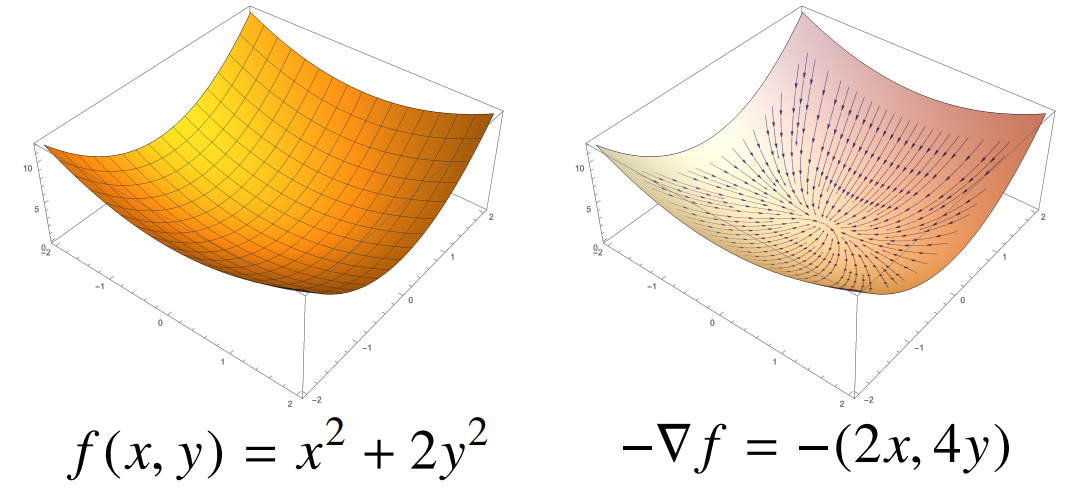
위의 그림을 보면 gradient vector는 각 점에서 가장 빨리 감소하는 방향으로 흐르는 것을 알 수 있다.



※ gradient vector python 코드
def eval_(fun, val):
val_x, val_y = val
fun_eval = fun.subs(x, val_x).subs(y, val_y)
return fun_eval
def fun_multi(val):
x_, y_ = val
func = sym.poly(x**2 + 2*y**2)
return eval_(func, [x_, y_]), func
def func_gradient(fun, val):
x_, y_ = val
_, function = fun(val)
diff_x = sym.diff(function, x) #x에 대해 미분
diff_y = sym.diff(function, y) #y에 대해 미분
grad_vec = np.array([eval_(diff_x, [x_, y_]), eval_(diff_y, [x_, y_])], dtype=float)
return grad_vec, [diff_x, diff_y]
def gradient_descent(fun, init_point, lr_rate=1e-2, epsilon=1e-5):
cnt = 0
val = init_point
diff, _ = func_gradient(fun, val)
while np.linalg.norm(diff) > epsilon:
val = val - lr_rate*diff
diff, _ = func_gradient(fun, val)
cnt += 1
print('함수: {}, 연산횟수: {}, 최소점: ({}, {})'.format(fun(val)[1], cnt, val, fun(val)[0]))
pt = [np.random.uniform(-2,2), np.random.uniform(-2,2)]
gradient_descent(fun=func_multi, init_point=pt)
#함수: poly(x**2 + 2*y**2, x, y, domain='zz'), 연산횟수: 606, 최소점: ([4.95901570e-06 2.88641061e-11], 2.45918366929856E-11)
gradient vector의 경우 weight update는 각 변수 기울기들의 L2-노름이 epsilon보다 클 때까지 반복한다.
4. 확률적 경사하강법(Stochastic Gradient Descent, SGD)
경사하강법은 미분가능하고 볼록(convex)한 함수에 대해서는 학습률과 학습횟수가 적절하다면 최소점으로 수렴한다는 것이 보장되어있다. 선형함수도 weight 즉 beta에 대해서 볼록함수를 가지기 때문에 최소점을 잘 찾아간다. 하지만 비선형함수나 목적식이 볼록하지 않은(non-convex) 경우 수렴이 보장되지 않는다.

이를 보완하기 위한 방법이 확률적 경사하강법이다. 확률적 경사하강법은 모든데이터를 한 번에 업데이트하지 않고 한개 또는 일부를 활용하여 업데이트하는 것을 말한다. 이때 데이터 일부를 미니배치라 한다.
■ SDG의 이점
· 첫번째는 데이터의 일부를 사용하기 때문에 연산 자원 측면에서 효율적이다. 하드웨어의 제한을 극복하고 병렬 계산이 가능하도록 하기 때문이다.
· 두번째는 매번 다른 미니 배치를 사용하므로 목적식이 다르다. 따라서 매번 다른 곡선을 가지게 되는데 이것은 gradient가 한 번 0에 도달하더라도 다른 미니배치가 다른 곡선을 통해 계속적으로 update할 수 있기 때문에 local minimum을 지날 수 있다.
■ SGD의 parameter update 과정

파란색은 데이터 전체에 대해 update하는 것이고(GD), 보라색은 데이터 1개씩 update하는 것이고(SGD), 초록색은 미니배치를 이용하여 update하는 것이다(SGD). 우선 보라색은 데이터 1개씩 update하면 과정이 너무 길고 경로가 비효율적이므로 제외하고 GD를 이용한 파란색과 SGD를 이용한 초록색을 비교해보자.
오른쪽의 그림 상으로는 SG가 가장 바람직한 경로를 따라가는 것 같지만 시간은 SGD보다 오래 걸린다. SGD는 미니배치마다 다른 곡선을 가지고 update하기 때문에 구불구불하게 찾아가는데 이것을 보완하기위해 이후 Momentum, Adagrad 등의 방법이 등장한다.
'AI > 딥러닝' 카테고리의 다른 글
| [Pytorch] Hyper-parameter Tuning , Pytorch Troubleshooting (0) | 2021.08.21 |
|---|---|
| [Pytorch] Multi-GPU (0) | 2021.08.21 |
| [Optimization] Generalization , Under-fitting vs Over-fitting , Cross Validation (0) | 2021.08.16 |
| weight를 갱신할 때 기울기에 왜 Learning rate를 곱할까? (2) | 2021.08.15 |
| [Optimizer] SGD , Momentum , NAG , Adagrad , Adadelta , RMSprop , Adam (3) | 2021.08.15 |




댓글