지난 포스팅에서 Retrieval with dense embedding에 대해 알아보았다. 간단히 보면, question과 passage 각각을 위한 encode있다. question은 질문이 들어올 때마다 encoding을 하고, passage는 확보한 것을 미리 연산한다. question이 들어올 때마다 미리 확보한 passage와 비교해서 question과 유사도가 높은 passage를 내보낸다.

embedding space에서 quesiton이 들어오면 그 question과 가장 거리가 가까운 passage들을 vector space에서 보게된다.
문제는 passage(파란색 점)가 많을 때, question과 유사한 passage를 어떻게 효율적으로 찾을 것인지이다. 이렇게 유사한 문서를 찾는 과정을 Similarity Search라 한다.
■ MIPS (Maximum Inner Product Search)
Similarity Search방법 중 Brute-force(exhaustive) search는 저장해둔 모든 Sparse/Dence임베딩에 대해 일일이 내적값을 계산하여 가장 큰 값을 갖는 Passage를 찾는 것이다. 실제로 검색해야할 데이터는 매우 방대하며, 위키피디아만 해도 5백만 개이며, 수십 억, 조 단위까지 커질 수 있다. 따라서 모든 문서 임베딩을 일일이 보며 검색할 수 없다.
■ Tradeoffs of similarity search
similarity search에는 시간, 공간, 정확성에 대한 3가지 문제가 tradeoff로 작용하게 된다.
아래 그림은 이 세 가지 문제에 대한 각각의 접근법이다.
정확성을 높이기 위해서는 exhaustive search를 사용할 수 있고, speed를 높이기 위해서는 pruning등의 경량화를 수행할 수 있다. memory 효율을 위해서는 compression기법을 적용할 수 있다.
아래 그림은 속도(search speed)와 재현율(recall)의 관계를 나타낸 그래프이다. 더 정확한 검색을 위해서는 많은 시간이 소요된다.
코퍼스의 크기가 커질 수록 search space도 커지고 검색이 어려우며 저장할 memory space또한 많이 요구된다. 이는 sparse embedding의 경우 더 심하다.

Approximating Similarity Search
■ 메모리
Compression - Scalar Quantization(SQ)
Compression이란 Vector를 압축하여 하나의 vector가 적은 용량을 차지하는 것을 말한다. 즉 압축량을 높이면서 메모리는 줄이는 것이다. 다만 정보 손실이 발생할 수 있다.

■ speed
Pruning - Inverted File (IVF)
Pruning이란 dataset의 subset만 방문하여 Search space를 줄이고 속도를 개선하는 것이다. 즉 Clustering + Inverted File을 활용한 search이다. Clustering은 전체 vector space를 k개의 cluster로 나누는 것이다. 대표적으로 k-means clustering방법이 있다.
clustering은 passage들을 정해진 cluster에 소속시켜 군집하는 것을 말한다. 오른쪽 그림으 보면 사각형의 Query가 들어왔을 때, 가장 근접한 cluster만 본다. 이 경우 3개의 cluster를 방문하며, 각 cluster에 있는 모든 passage들은 Exhaustive search로 모두 본다.

이를 Inverted File이라 부르는 이유는 cluster내에서 역으로 vector들의 index를 가지고 있기 때문이다. 각 cluster의 centroid id와 해당 cluster의 vector들이 연결되어 있는 형태이다.
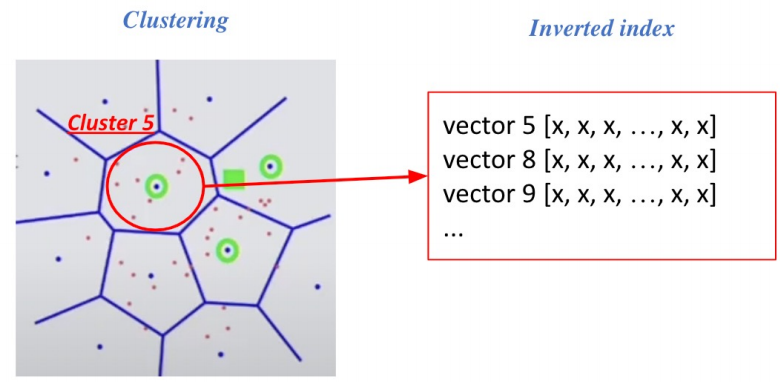
정리하면, 아래 그림과 같다.

FAISS
Faiss란?

- FAISS github: https://github.com/facebookresearch/faiss
- FAISS tutorial: https://github.com/facebookresearch/faiss/tree/main/tutorial/python

※ FAISS는 인덱싱을 도와주는 것이지 임베딩을 도와주는 것이 아님
벡터를 확보하고 나면, 이 벡터들을 training한다. 그 이유는 FAISS를 사용하기 위해서는 Clustering을 확보해야 한다.
Clustering을 위해 어떤 벡터가 서로 유사한지 알아야 하고, 이를 위해 index training이 필요하다. 또한 Scalar Quantization(SQ)을 할 때(float32 to int8)도 float의 min, max값을 기반으로 scale, offset을 결정해야하므로 index training이 요구된다.

이렇게 index training이 끝나고 Cluster와 SQ8을 확보하면, 이제 이 Cluster안에 SQ8의 형태로 index들을 넣어준다.
따라서 크게 Train index와 Add index로 나뉜다.
■ Search based on FAISS index
이렇게 FAISS index가 만들어지면, Inference단계에서 query가 들어오고 검색을 한 후 가장 가까운 cluster를 방문해서 cluster 내의 vector을 일일이 비교하여 top-k의 문서 벡터를 추출한다.
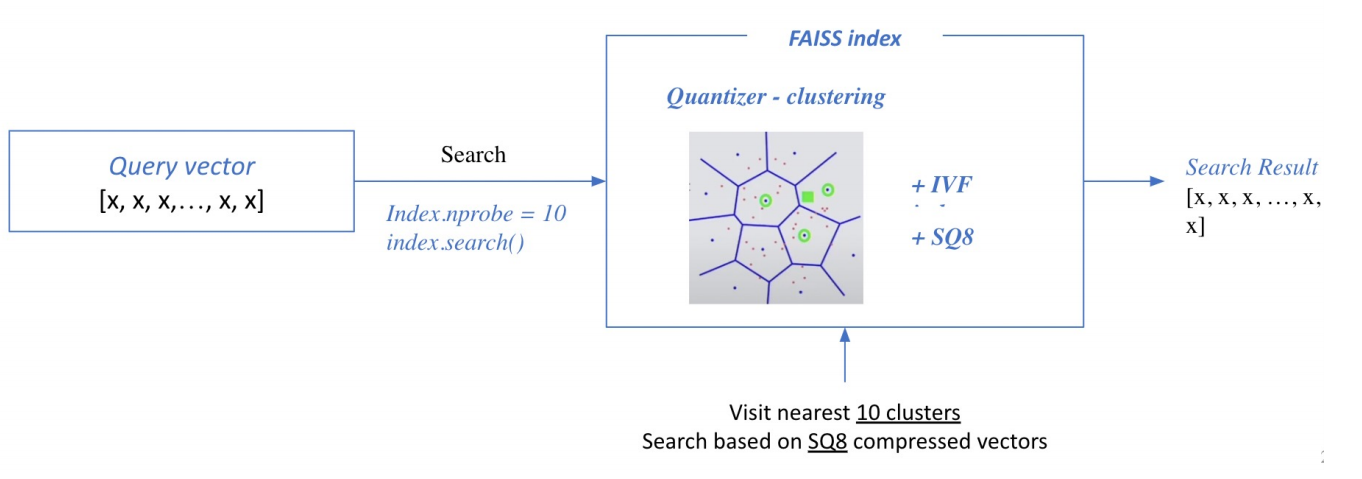
Scaling up wiht FAISS
■ FAISS basic
brute-force로 모든 쿼리와 벡터를 비교하는 단순한 인덱스 만들기
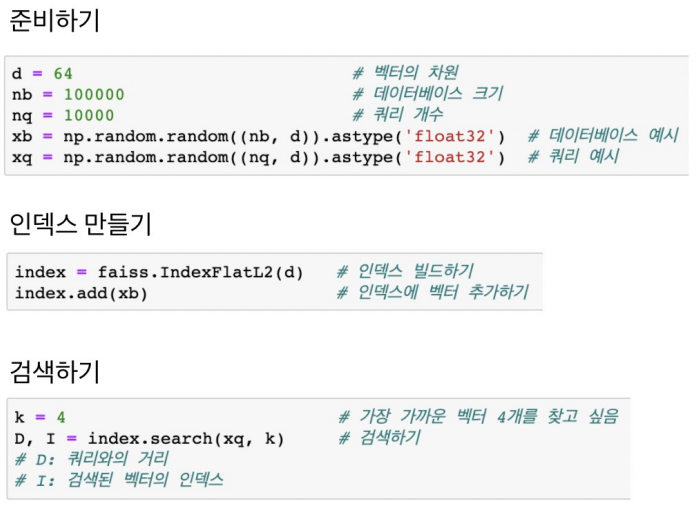
※ Pruning과 SQ작업이 없으므로 Training할 필요 없음
■ IVF with FAISS
- IVF 인덱스 만들기
- Clustering을 통해 가까운 Cluster내 벡터들만 비교하여 빠른 검색
- Cluster내에는 여전히 전체 벡터와 거리 비교 (Flat)

※ quantizer는 클러스터끼리 거리를 잴 때 어떻게 잴 때 L2사용
■ IVF-PQ with FAISS
- 벡터 압축 기법(PQ) 활용
- 전체 벡터를 저장하지 않고 압축된 벡터만 저장
- 메모리 사용량 줄일 수 있음

■ Using GPU with FAISS
- GPU의 빠른 연산 속도를 활용하므로 거리 계산을 위한 행렬곱 등에서 유리
- GPU메모리 제한 및 메모리 Random Access시간이 느린 것 등이 단점

■ Using Multiple GPUs with FAISS
여러 GPU를 활용하여 연산 속도를 더 높일 수 있음

'AI > 딥러닝' 카테고리의 다른 글
| [최적화] AutoML , Surrogate Model , Acquisition Function (0) | 2021.11.23 |
|---|---|
| [최적화] 모델 경량화 , AutoML , Pruning , Knowledge Distillation , Tensor Decomposition , Quantization , Compiling (0) | 2021.11.22 |
| [MRC] Passage Retrieval – Dense Embedding (0) | 2021.10.17 |
| [MRC] Passage Retrieval – Sparse Embedding (0) | 2021.10.17 |
| [MRC] Generation-based MRC (0) | 2021.10.13 |




댓글