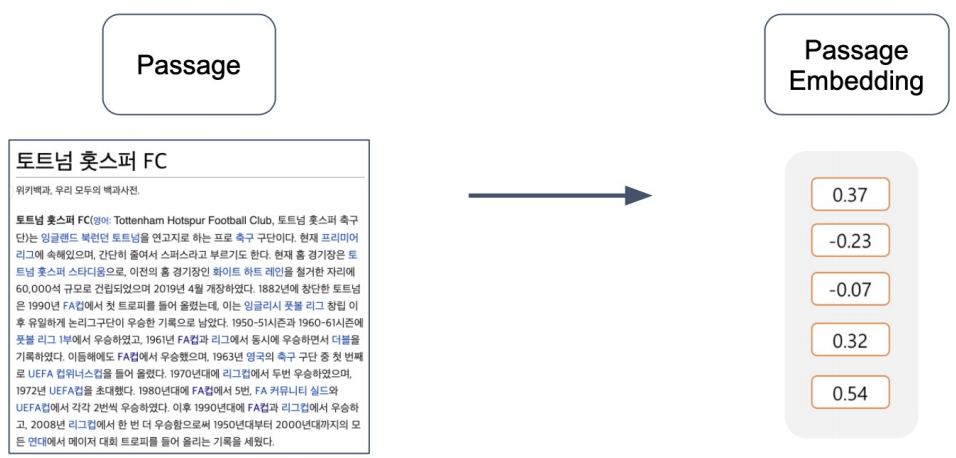
Passage Retrieval을 위해 Passage를 적절한 벡터로 변환하는 Passage Embedding에 대해 알아볼 것이다. 지난 포스팅에서는 Sparse Embedding에 대해 다루었고, 이번에는 Dense Embedding에 대해 살펴볼 것이다.
먼저 Sparse Embedding에서 배운 TF-IDF는 Bag-of-Word를 기반으로 하기 때문에 zero value가 많고, 벡터 차원이 굉장히 크다. 그러나 이 부분은 non-zero의 위치와 값만 저장하는 등의 compressed format으로 극복 가능하다.
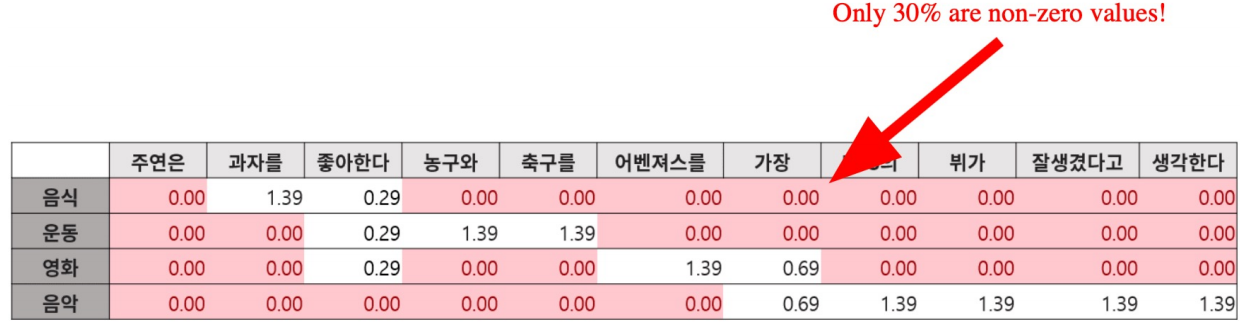
Sparse Embedding의 장 큰 문제점은 단어간 유사성을 고려하지 못한다는 것이다. 같은 의미를 갖는 다른 단어는 완전히 다른 벡터로 임베딩 되며, vector space에서도 유사성을 고려할 수 없는 형태가 된다.
이런 단점을 보완한 방식으로 Dense Embedding이 있다.
Dense Embedding
■ Sparse Embedding VS Dense Embedding
Sparse Embedding은 보통 vocab size길이의 벡터를 갖는 반면, Dense Embedding은 50~1000정도의 작은 차원의 고밀도 벡터를 갖는다. 또한 각 차원이 특정 term에 대응되지 않고 합쳐진 하나의 벡터의 vector space상의 위치가 의미를 가진다.
아래 그림의 왼쪽은 Sparse Embedding이고 오른쪽은 Dense Embedding이다. Sparse Embedding은 각 차원이 term으로 구성되어 있으며, zero value가 많다. 반면 Dense Embedding은 굉장히 compact하며 대부분 non-zero value로 채워져있다.

이외에도 아래 그림과 같은 차이점이 존재한다.
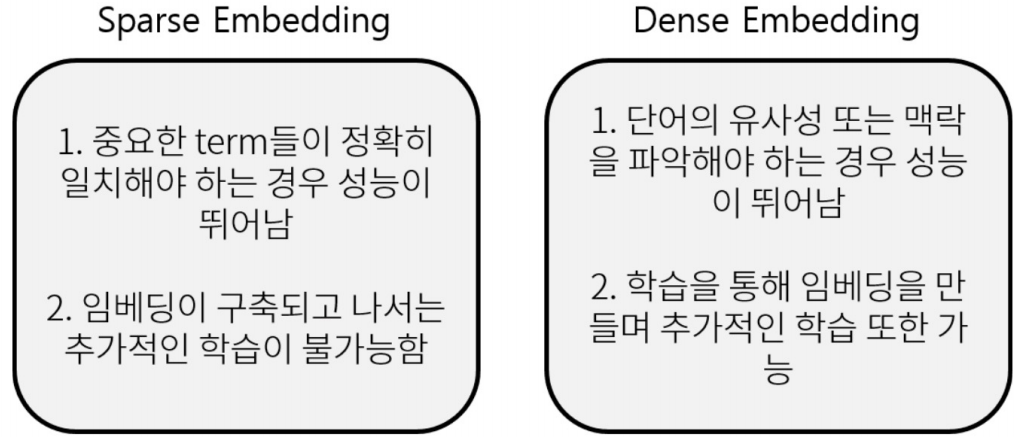
※ 학습을 통해 Embedding을 구축하는 Dense Embedding의 경우, 사전 학습 모델의 등장으로 더 활발히 사용되고 있다.
■ Overview of Passage Retrieval with Dense Embedding
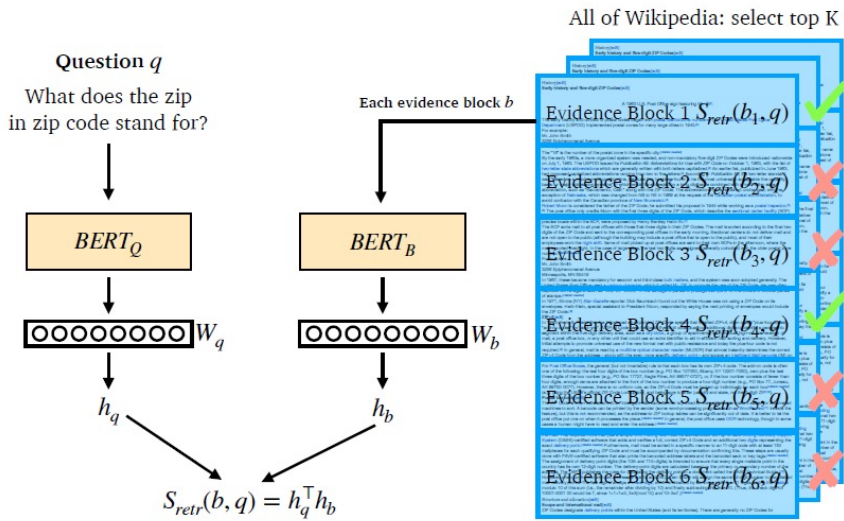
Question과 Passage모두 각각의 weight를 가진 encoder를 통해 [CLS] 토큰에 해당되는 Embedding을 얻는다. 이를 각각hq, hb라 하며, 이 둘을 내적하여 유사도를 계산한다. 이 과정을 모든 Passage에 대해 수행한 후, 가장 높은 유사도를 갖는 Passage를 선택한다.
Training Dense Encoder
Dense Encoder는 보통 Bert와 같은 Pre-trained Language Model (PLM)을 사용한다.
ex) Bert의 경우, [CLS]토큰의 output을 이용하여 Vector를 얻는다.
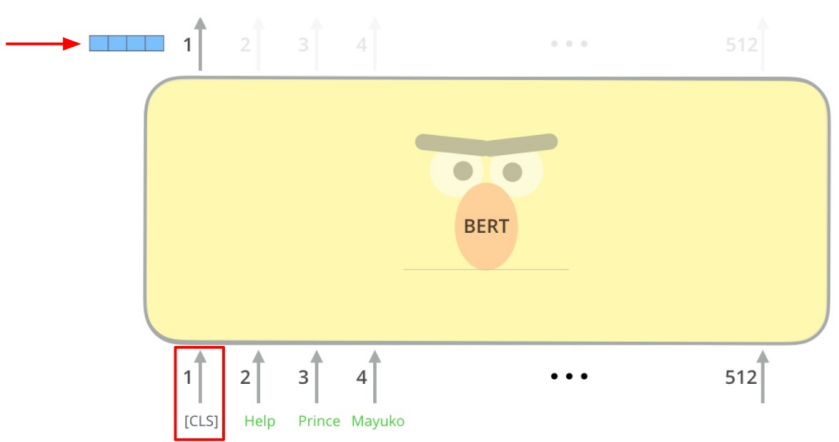
■ Dense Encoder의 학습 목표와 데이터셋
- 학습 목표: 관련있는 question과 passage dense embedding의 거리를 좁히는 것, inner product를 높이는 것
- 데이터셋: MRC데이터셋 활용
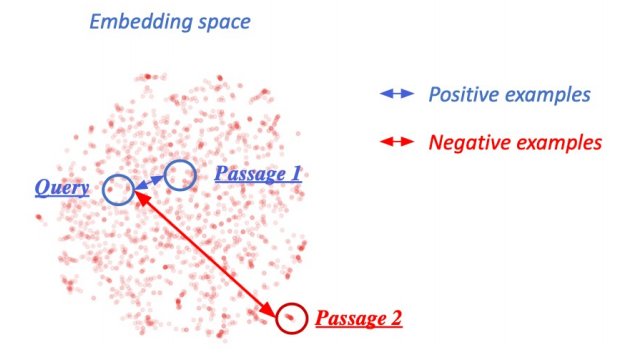
■ Negative Sampling
- Negative Sampling 개념알기 → https://wikidocs.net/69141
- 학습과정: 관련있는 question과 passage의 embedding거리는 좁히고(positive), 관련 없는 question과 passage의 embedding거리는 멀게해야 한다(negative).
- negative examples선택 방법
- corpus내에서 랜덤 추출
- TF-IDF점수가 높지만 답을 포함하지 않는 헷갈리는 sample선택
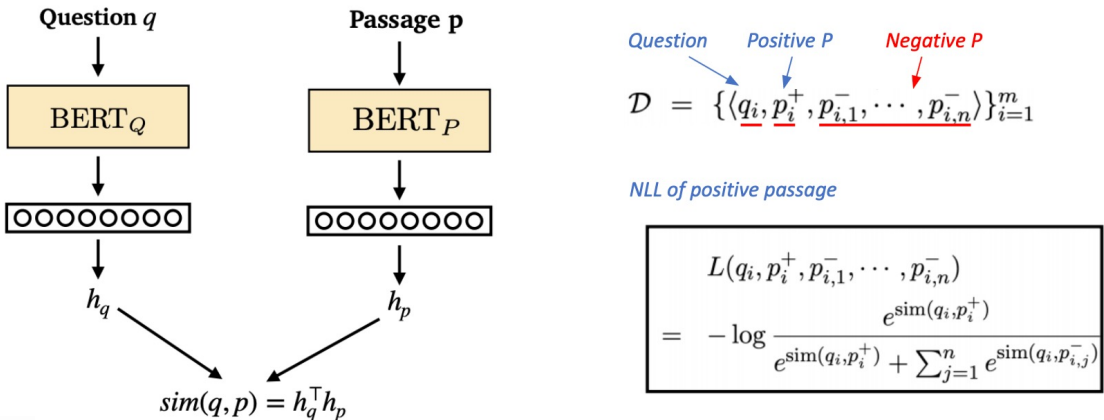
■ Object Function
negative sampling에 corss entropy를 사용한 Negative Log Likelihood를 Loss로 사용한다.
[참고]
- https://www.youtube.com/watch?v=i5U2inxzXx4
- https://ratsgo.github.io/deep%20learning/2017/09/24/loss/
- [in-batch negative sampling & loss] https://github.com/facebookresearch/DPR/issues/110
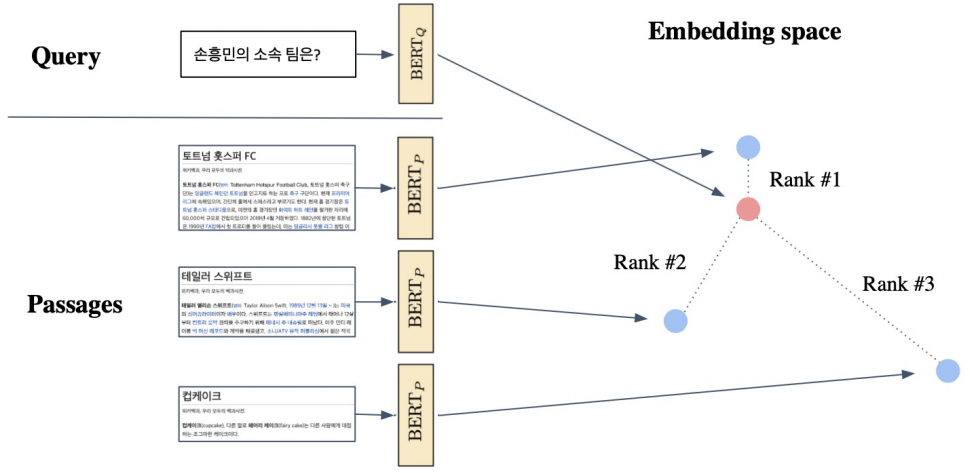
■ Inference
Passage와 Query을 미리 Embedding해둔 것에 대해, Query로부터 가까운 거리에 있는 Passage의 순위를 매긴다.
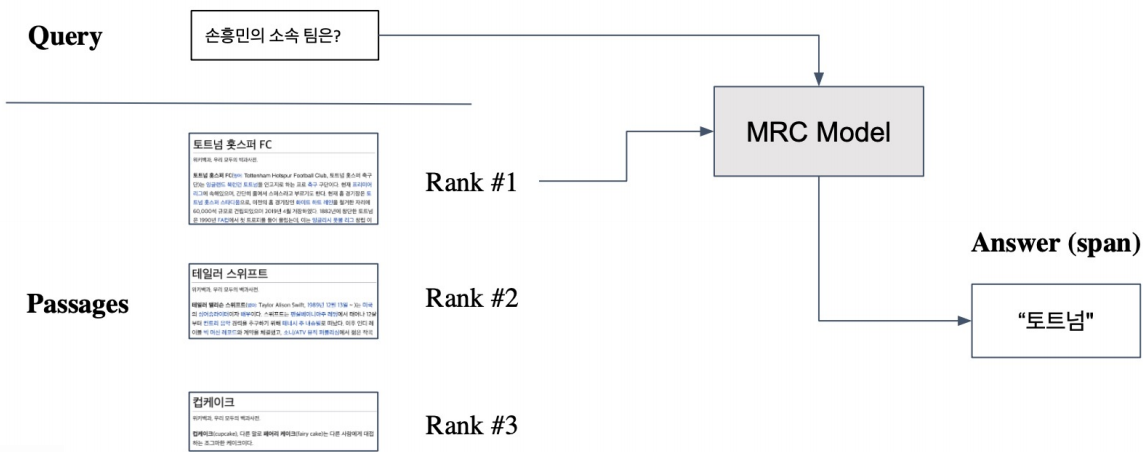
■ ODQA로 확장
Retriever를 통해 Passage를 찾은 후, MRC모델로 질문에 대한 답변을 찾는다.
■ Dense Encoding 개선 방향
- 학습 방법 개선: DPR 등
- Encoder 모델 개선: 더 크고 정확한 Pretrained모델 등
- 데이터 개선: 데이터 추가, 전처리 등
'AI > 딥러닝' 카테고리의 다른 글
| [최적화] 모델 경량화 , AutoML , Pruning , Knowledge Distillation , Tensor Decomposition , Quantization , Compiling (0) | 2021.11.22 |
|---|---|
| [MRC] Retrieval, Scaling up with FAISS (2) | 2021.10.17 |
| [MRC] Passage Retrieval – Sparse Embedding (0) | 2021.10.17 |
| [MRC] Generation-based MRC (0) | 2021.10.13 |
| [MRC] Extraction-based MRC (0) | 2021.10.13 |




댓글