AutoML Motivation
Conventional Deep Learning Training Pipeline → AutoML
일반적으로 Data Engineering이라 함은, Data cleansing 및 Preprocessing과 Feature Engineering을 하고 적절한 ML알고리즘을 선택한 후 Hyperparameter를 튜닝한다.

좋은 configuration이 나올 때까지 모델을 선정하고 Hyperparameter를 설정하여 Train과 Evaluate을 하는 작업을 반복한다.

이 과정을 사람이 계속 반복하는데, AutoML로 이 반복 구조에서 사람의 노고를 뺀 진정한 End-to-end learning을 실현하고자 한다.

AutoML 기본 개념
AutoML(Hyperparameter Optimization, HPO)의 정의

Deep learning model configuration
- Categorical
- optimizer : Adam, SDG, AdamW, · · ·
- model : Vanilla Conv, Bottleneck, InvertedResidual, · · ·
- integer : batch_size, epochs, · · ·
- Conditional (특정 configuration에 따라 search space가 달라짐)
- optimizer sample에 따라서 optimizer parameter의 종류, search space가 달라짐
- optimizer에 따른 learning rage range차이, SDG의 경우 momentum, Adam의 경우 alpha, beta1, beta2 등)
- Module의 sample에 따라 module parameter의 종류, search space가 달라짐
- optimizer sample에 따라서 optimizer parameter의 종류, search space가 달라짐
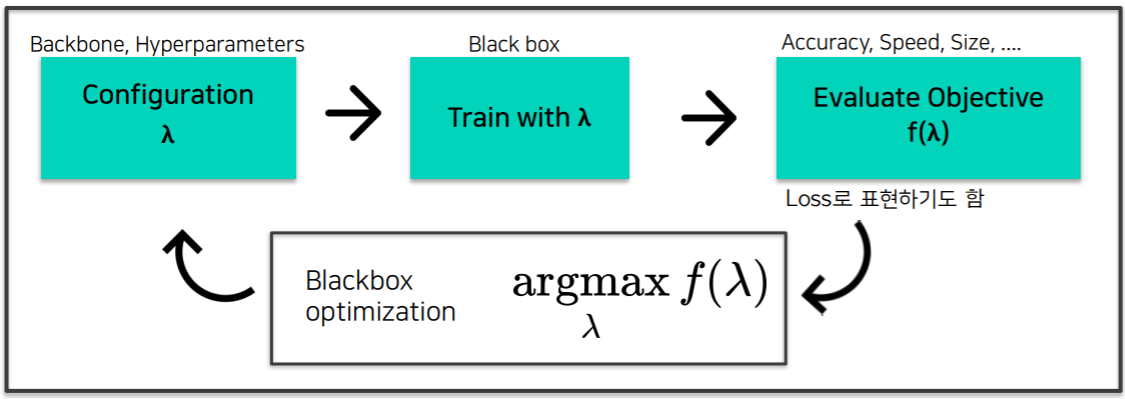
AutoML Pipeline
- 일반적인 AutoML Pipeline
- Backbone, Hyperparameter등의 configuration $\lambda$를 정하고 학습한 후 속도, 크기, 성능 등 요구사항에 따른 목적함수 f에 대해 함수값 $f(\lambda)$ 를 구한다. Blackbox안에서 함수값$f(\lambda)$ 를 최대화하는 $\lambda$를 찾으며 이 과정을 반복한다.
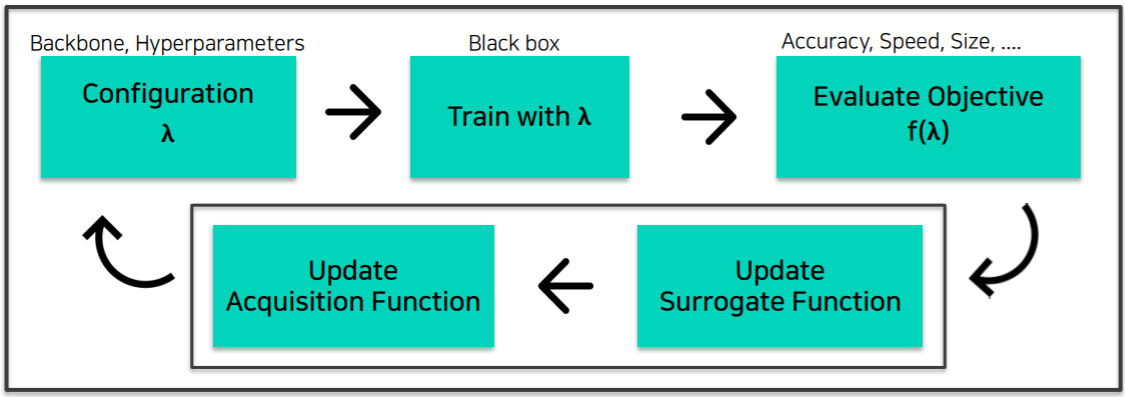
- AutoML Bayesian Optimization(BO) Pipeline
- BO에서는 위의 일반적인 AutoML Pipeline에서의 Blackbox optimization이 두 단계에 거쳐 수행된다.
- Surrogate Function : $f(\lambda)$ 의 regression model이다.
- 즉, $f\left(\lambda^{*}\right)$를 예측함으로써 Acquisition에서 $\lambda^{*}$를 찾을 기준을 마련한다.
- Acquisition Function : 다음 어떤 $\lambda$를 시도해보면 좋을지 예측하는 모델이다.
- Surrogate Function : $f(\lambda)$ 의 regression model이다.
- BO에서는 위의 일반적인 AutoML Pipeline에서의 Blackbox optimization이 두 단계에 거쳐 수행된다.
Surrogate Function은 실선과 보라색 영역을 나타내며, Acquistion Function은 초록색 영역을 나타낸다.

Surrogate Model 및 Acquisition Function 상세
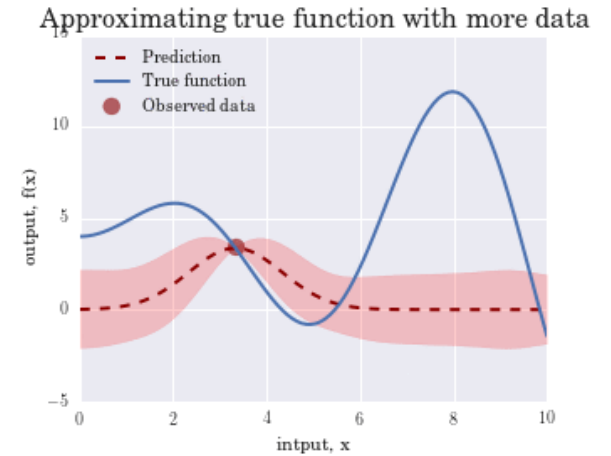
Surrogate Model
- $f(\lambda)$ 의 Regression model로 $f(\lambda)$ 값을 예측
- 지금까지 관측된 $f(\lambda)$ 들이 있을 때, 새로운 $\lambda^{*}$ 에 대한 objective $f\left(\lambda^{*}\right)$ 는 얼마일까?
- objective를 estimate하는 Surrogate model을 학습하여 이후 좋은 $\lambda$를 선택하는 기준을 마련
- Gaussian Process Regression(GPR) Model이 대표적인 Surrogate model이다.
- Mean : 예측 f값
- Var : uncertainty
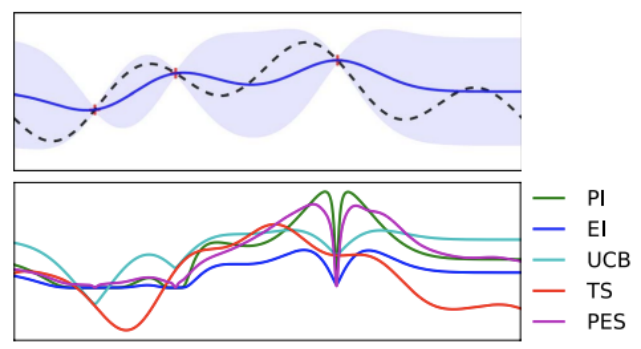
Acquisition Function
- 다음은 어떤 값으로 시도해보면 좋을까?
- Surrogate model의 output으로부터 다음 시도할 $\lambda$ 를 계산하는 함수
- Exploration : 불확실한 지점 탐험 (분산↑)
- Exploitation : 알고있는 가장 좋은 지점 공략 (평균↑)
- Exploration vs Exploitation trade off : 두 가지를 balancing하여 Acquisition function구성
- Acquisition function의 max지점을 다음 iteration에서 시도
- Upper Confidence Bound(UCB)가 대표적인 Acquisition function이다.
- $\alpha_{t}=\mu_{t-1}+\kappa \sigma_{t-1}$
- $\mu_{t-1}$ : posterior mean(Exploitation)
- $\sigma_{t-1}$ : posterior variance(Exploration)
- K : parameter(balance)
- $\alpha_{t}=\mu_{t-1}+\kappa \sigma_{t-1}$
Surrogate Model 종류
Gaussian Process Regression(GPR)
- 일반적인 Regression task
- data에 가장 적합한 function 찾기
- train dataset : (X, Y)
- test dataset : (X*, Y*)
- $Y \approx f(X)+e$
- Gaussian Process Regression
- motivation : 알고자 하는 Y*는 알고 있는 X, Y, X*와 positive든 negative든 관련있지 않을까?
- X, Y, X*로 부터 Y*를 추정
- 연관에 대한 표현은 Kernal함수 K
- f(x)는 x가 주어졌을 때 가능한 함수인 random variable이며, 각 random variable은 Multivariate Gaussian Distribution따르는 것을 가정
- f(x)는 Gaussian process를 따름
알고자하는 값(test) $f_{*} \approx Y_{*}$ 과 알고 있는 값(train) $f \approx Y$ 의 관계는 아래와 같이 정의한다.
$$ \left[\begin{array}{l} \mathbf{f} \\ \mathbf{f}_{*} \end{array}\right] \sim \mathcal{N}\left(\mathbf{0},\left[\begin{array}{ll} K(X, X) & K\left(X, X_{*}\right) \\ K\left(X_{*}, X\right) & K\left(X_{*}, X_{*}\right) \end{array}\right]\right) $$
Gaussian distribution은 Marginal과 Contional distribution도 Gaussian이라는 가정을 두고 있다.
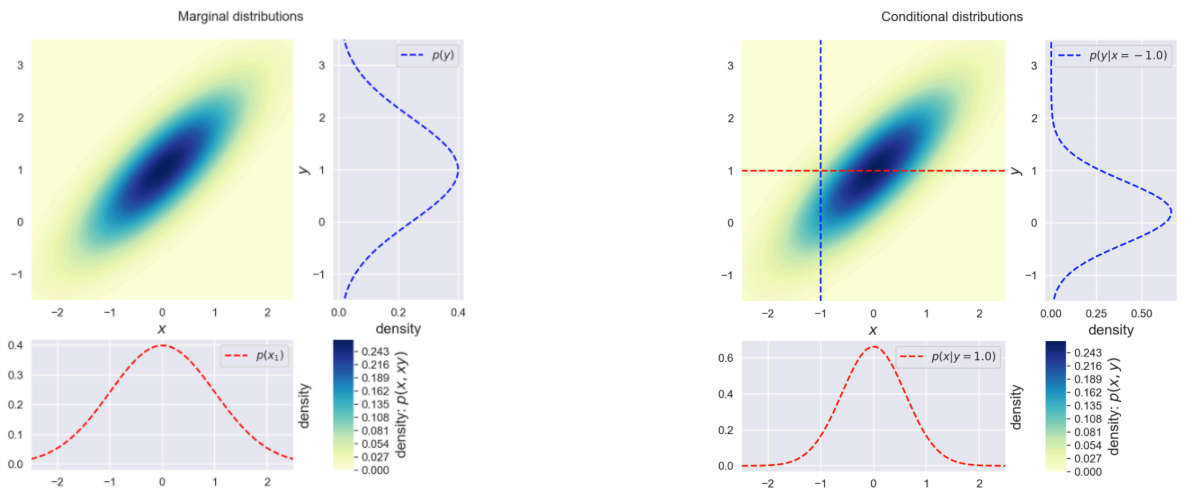
이 가정에 의해 X*, X, f를 알고 있으면 f*도 알 수 있으며, 그 분포는 아래와 같다.
$$
\begin{aligned}
&\mathbf{f}_{*} \mid X_{*}, X, \mathbf{f} \sim \mathcal{N}\left(K\left(X_{*}, X\right) K(X, X)^{-1} \mathbf{f},\right. \\
&\left.\qquad K\left(X_{*}, X_{*}\right)-K\left(X_{*}, X\right) K(X, X)^{-1} K\left(X, X_{*}\right)\right)
\end{aligned}
$$
※ 참고 : https://distill.pub/2019/visual-exploration-gaussian-processes/
A Visual Exploration of Gaussian Processes
How to turn a collection of small building blocks into a versatile tool for solving regression problems.
distill.pub
Tree-structured Parzen Estimatior(TPE)
[reference]

'AI > 딥러닝' 카테고리의 다른 글
| [최적화] Data Augmentation , AutoML (0) | 2021.12.15 |
|---|---|
| [최적화] Optuna , Yaml에서 Model 생성 (0) | 2021.11.25 |
| [최적화] 모델 경량화 , AutoML , Pruning , Knowledge Distillation , Tensor Decomposition , Quantization , Compiling (0) | 2021.11.22 |
| [MRC] Retrieval, Scaling up with FAISS (2) | 2021.10.17 |
| [MRC] Passage Retrieval – Dense Embedding (0) | 2021.10.17 |




댓글