1. ReLU 계층 구현 (forward/ backward)
활성화 함수 중 하나인 ReLU함수는 아래와 같다.
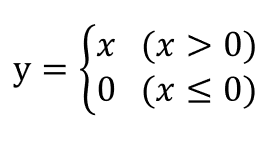
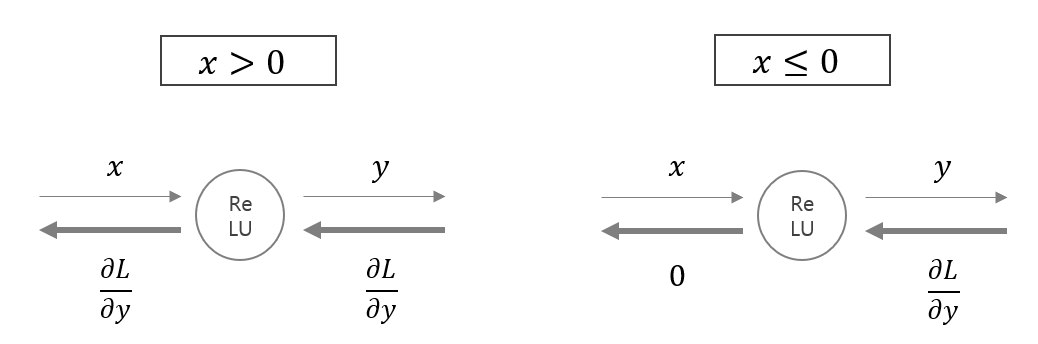
순전파에서 입력이 x > 0이면 역전파에서 upstream 값을 그대로 downstrem으로 보내는 반면, 입력이 x <= 0이면 역전파에서 upstream 값을 downstream으로 보내지 않는다.
<코드>
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
★핵심은 입력값이 x <= 0인 인덱스를 순전파 때 0으로 만들고, 역전파 때도 0으로 만들어 활성화되지 않도록 만드는 것이다.
인스턴스 변수 mask는 순전파의 입력인 x의 원소 값이 x <= 0인 인덱스는 True, x > 0인 인덱스는 False로 만든다. 예를 들면 아래와 같다.


forward에서 x의 원소 중 True값이 있는 인덱스, 즉 x <= 0인 인덱스에는 0값을 대입한다.
backward에서 upstream에서 전파된 dout의 원소 중 Ture값을 가진 인덱스에 0을 대입한다.
2. Sigmoid 계층 구현 (forward/ backward)
활성화 함수 중 또 다른 함수인 Sigmoid함수는 아래와 같다.
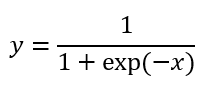
아래 그림은 Sigmoid계층의 계산 그래프이다.


위에서 미분한 값을 연쇄적으로 곱하면서 아래로 내려오며, '+'노드는 upstream의 값을 그대로 downstream으로 내보낸다.
역전파의 최종값은 아래와 같이 정리할 수 있다.
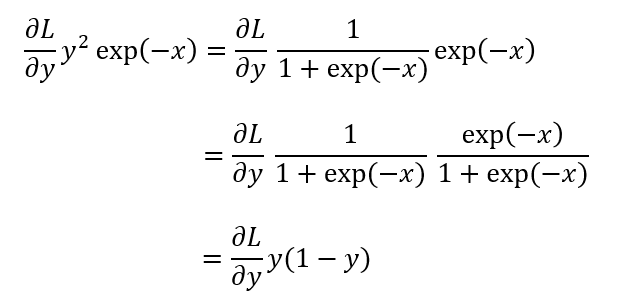

즉 Sigmoid 계층의 backpropagation은 순전파의 출력값 y만으로 계산할 수 있다.
<코드>
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
★핵심은 순전파의 출력값을 out에 담아서 역전파에서 활용하는 것이다.
출처: 사이토 고키, 『밑바닥부터 시작하는 딥러닝』, 한빛미디어(2017), p165-170.
https://www.hanbit.co.kr/store/books/look.php?p_code=B84758311980
'AI > 밑딥' 카테고리의 다른 글
| 딥러닝) 신경망 학습 전체 알고리즘 (코드) (0) | 2021.03.18 |
|---|---|
| 딥러닝) Affine , Softmax , Cross Entropy Error 계층 구현 (0) | 2021.03.16 |
| 딥러닝) 오차 역전파 backpropagation , 연쇄법칙 chain rule , 기울기 효율적으로 구하기 (0) | 2021.03.08 |
| 딥러닝) 신경망 학습 알고리즘 , Stochasitc Gradient Descent , epoch, iteration , batch size (0) | 2021.03.02 |
| 딥러닝) 기울기 , 경사하강법 , gradient descent , learning rate (0) | 2021.02.27 |



댓글