728x90
반응형
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Abstract
- BERT는 모든 layer에서 unlabeled data로부터 왼쪽과 오른쪽의 문맥을 모두 반영하는 bidirectional representation을 pre-training한다.
- 그 결과 Substantial task-specific architecture없이 pre-trained BERT모델에 하나의 output layer만 추가하여 질의응답, 언어유추 등 11개의 NLP Task에서 state-of-the-art를 달성하였다.
1. Introduction
- Language model pre-training은 sentence-level tasks와 token-level tasks를 포함한 다양한 NLP task를 향상하는데 효과적이었다.
- pre-trained language representation을 down-stream tasks에 적용하기 위한 두 가지 approach가 있다. feature-based approach와 fine-tuning approach이다.
- feature-based approach는 pre-trained representation을 추가적인 features로 task-specific architectures에 포함한다. (ex. ELMo)
- fine-tuning approach는 모든 Pre-trained parameters를 down-stream tasks에 학습시키고, 최소한의 task-specific parameters를 도입한다. (ex. OpenAI GPT)
- 위의 두 접근법은 unideirectional language models로 pre-training하며, 같은 목적 함수를 사용한다.
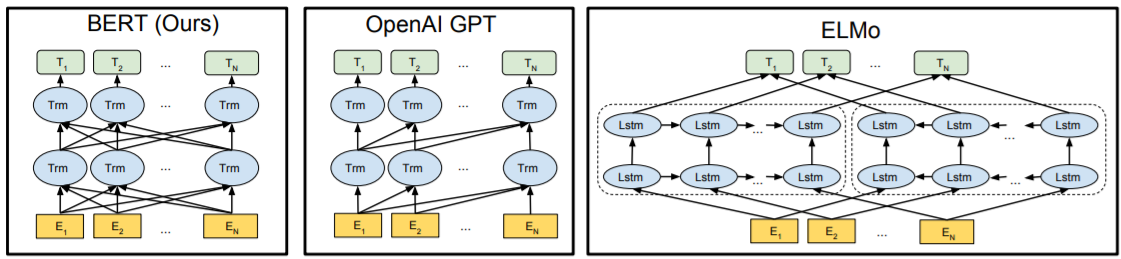
- BERT는 기존 방법들이 unidirectional한 한계점으로 인해 pre-trained representation을 잘 나타내지 못한다고 지적한다.
- left-to-right architecture를 사용하는 OpenAI GPT의 경우, 모든 token은 self-attention layers에서 이전의 tokens만 참조할 수 있다.
- 이는 sentence-level task 또는 양방향의 context를 통합하는 것이 중요한 question-answering task에서 sub-optimal하거나 harmful할 수 있다.
- BERT는 masked language model(MLM)을 사용하여 unidirectionality를 완화하며, fine-tuning based접근법을 향상한다.
- MLM은 representation이 양방향의 context를 융합하므로 bidirectional Transformer를 pre-training할 수 있다.
- BERT의 두 가지 task는 token-level task인 masked language model(MLM)과 sentence-level task인 next sentece prediction(MSP)이다.
2. Related Work
Unsupervised Feature-based Approaches: ELMo
Unsupervised Fine-tuning Approaches: OpenAI GPT
3. BERT
- BERT의 framework에는 두 가지 절차 pre-training과 fine-tuning이 있다.
1. pre-training
unlabeled data로 사전 학습
2. fine-tuning
사전 학습된 모델의 parameter로 초기화한 후 down-stream task의 labeled data로 parameter를 fine-tuning
- 각각의 down-stream task는 동일한 pre-trained parameters로 초기화하며 개별적인 fine-tuned model을 가진다.
Model Architecture
- BERT의 구조는 multi-layer bidirectional Transformer encoder이다.
- BERT base와 BERT large 모델의 사이즈 (L=layer 개수, H=hidden 사이즈, A=self-attention heads 개수)
1. BERT base
L=12, H=786, A=12, Total Parameters=110M
2. BERT large
L=24, H=1024, A=16, Total Parameters=340M
- BERT base의 크기는 OpenAI GPT와 동일하게 하였다. BERT의 Transformer는 bidirectional self-attention을 사용하였고, GPT의 Transformer는 left context만 참조 가능한 constrained self-attention을 사용하였다.
Input/Output Representation
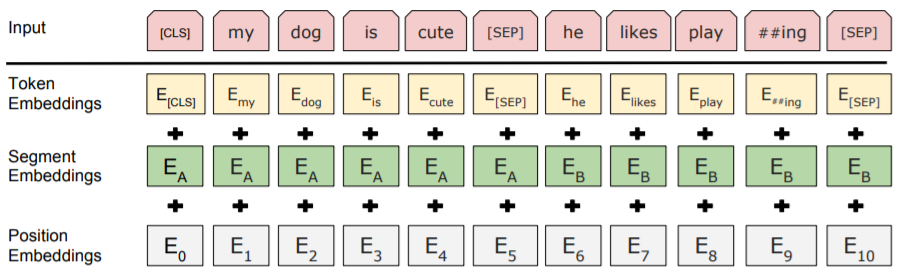
- BERT모델의 입력 단위인 sentence는 single sentence 또는 two sentences packed together이다.
- 모든 sequence의 첫번째 token은 classification token인 [CLS]이다. [CLS]에 해당하는 마지막 hidden state는 classification을 위한 sequence representation이다.
- two sentenes packed together를 구분하기 위해, [SEP] token과 두 sentence 중 어디에 속한 token인지를 나타내는 segment embedding을 사용한다.
- input representation은 token embedding, segment embedding, positional embedding의 합으로 나타낸다.
3.1 Pre-training BERT
- BERT는 Masked Language Model과 Next Sentence Prediction 이 두 가지 unsupervised tasks를 사용하여 pre-training한다.
- BooksCorpus와 English Wikipedia data로 학습한다.
- input embedding = E
- final hidden vector of the special [CLS] token = $C \in \mathbb{R}^{H}$
- i번째 input token의 final hidden vector = $T_{i} \in \mathbb{R}^{H}$

Task #1: Masked Language Model(MLM)
- Bidirectional model은 left-to-right model 또는 left-to-right model과 right-to-left model을 합친 shallow concatenation보다 훨씬 강력하다.
- Bidirectional representation을 학습하기 위해 아래의 작업을 수행한다.
- WordPiece token의 15%를 masking한다.
- masked words만 예측하며, fine-tuning에는 [mask] token이 없으므로 pre-training과 fine-tuning간 mismatch가 발생한다.
- 이 문제점을 완화하기 위해 masked words를 [mask] token으로만 대체하지 않고 다양한 방식으로 대체한다.
- 전체 WordPiece token의 15% 중 80%는 [mask] token으로 대체하고, 10%는 random token으로 대체하고, 10%는 바꾸지 않고 원래 token으로 유지한다.

Task #2: Next Sentence prediction(NSP)
- Question Answering, Natural Language Inference task는 두 sentence간 relationship을 기반으로 한다. 이 relationship을 학습하기 위해 binarized next sentence prediction task를 사전 학습한다.
- sentence A와 B를 선택할 때, B의 50%는 A 다음 순서에 오는 문장으로 선택하고, 50%는 순서와 상관없이 random으로 선택한다.
- A 다음에 올 문장이면 IsNext 그렇지 않으면 NotNext로 labeling한다.
- 마지막 hidden state의 C token은 next sentecne prediction에 사용된다.

3.2 Fine-tuning BERT
- Fine-tuning은 빠르고 간단하며, 대부분의 hyperparameter는 pre-training의 hyperparameter와 같다.
- 보통 text pair task를 위해 bidirectional cross attention을 적용하기 전에 sentence 각각을 encoding을 한다.
- BERT의 경우, self-attention이 두 단계를 통합하므로 concatenated text pair를 self-attention으로 encoding하는 것은 bidirectional cross attention적용을 포함한다.
- token representations은 sequence tagging, QA같은 token level tasks를 위한 output layer에 들어가고
- [CLS] representations은 entailment, sentiment analysis같은 classification을 위한 output layer에 들어간다.
- fine-tuning을 위해 추가되는 parameter는 classification layer weights $W \in$ $\mathbb{R}^{K \times H}$이다. (K = label의 수)
- 보통 classification loss는 C와 W로 계산된다. i.e., $\log \left(\operatorname{softmax}\left(C W^{T}\right)\right)$
3.3 Pre-training Procedure
- 첫번째 sampling한 sentence에 A segment embeddidng 더하고, 두번째 sampling한 sentence에 B segment embeddidng을 더한다.
- B의 50%는 A 다음 순서에 오는 IsNext문장이다. 나머지 50%는 순서와 상관없는 NotNext문장이다.
- A와 B의 length 합은 512이하가 되어야 한다.
- LM masking은 WordPiece tokenization 후에 적용한다.
- batch size = 256
- epochs = 40
- learning rate = 1e-4
- optimizer = Adam ($\beta_{1}$ = 0.9, $\beta_{2}$ = 0.999)
- L2 weight decay = 0.01
- dropout = 0.1
- activation function = gelu
- loss funtion = the mean LM masked likelihood와 the mean Next Sentence Prediction likelihood의 합
- BERT base = 4 Cloud TPUs , 4일 동안 학습
- BERT large = 16 Cloud TPUs , 4일 동안 학습
3.4 Fine-tuning Procedure
- dropout = 0.1로 유지하고, batch size, learning rate, epochs의 optimal hyperparameter는 task-specific하지만 아래의 값으로 설정하면 대부분 잘 학습한다.
- batch size = 16, 32
- optimizer = Adam
- learning rate = 5e-5, 3e-5, 2e-5
- epochs = 2, 3, 4
[reference]
https://arxiv.org/pdf/1810.04805.pdf
728x90
반응형
'Reading papers > NLP 논문' 카테고리의 다른 글
| Continual Learning for Generative Retrieval over Dynamic Corpora (0) | 2023.09.07 |
|---|---|
| G-Eval (0) | 2023.08.16 |
| [논문 리뷰] SEAL: Autoregressive Search Engines: Generating Substrings as Document (0) | 2023.03.26 |
| [논문 요약] SOM-DST: Efficient Dialogue State Tracking by Selectively Overwriting Memory (0) | 2022.02.04 |




댓글